
Inware 7.0 Update Revolutionizes Android Device Information with Material 3 Expressive Redesign and Advanced Diagnostics.
The popular Android device information application, Inware, has rolled out a substantial update this week, version 7.0, introducing a comprehensive Material 3 Expressive design overhaul alongside a suite of significant new features. This pivotal update, freely accessible via the Google Play Store, further solidifies Inware’s reputation as a go-to utility for Android users seeking detailed insights into their device’s hardware and software specifics. The enhancement goes beyond mere aesthetic refinements, integrating crucial diagnostic tools that empower users with an unprecedented level of transparency regarding their smartphone’s operational health and capabilities.
Inware has long been lauded for its ability to distill complex technical data into an easily digestible format. Prior iterations of the app already provided essential metrics such as storage capacity, available memory, detailed camera sensor specifications, display parameters (including resolution and refresh rates), and charging speed. Version 7.0 significantly builds upon this foundation by introducing new data points that cater to the evolving demands of modern smartphone usage and emerging technological standards. These additions include the monitoring of active thermal throttling, detection of 6GHz Wi-Fi utilization, identification of Thread connectivity, and the display of a battery cycle count. Each of these features offers valuable diagnostic capabilities, allowing users to better understand their device’s performance, connectivity, and long-term health.
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2026/04/inware-7.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
Aesthetic Transformation: Embracing Material 3 Expressive
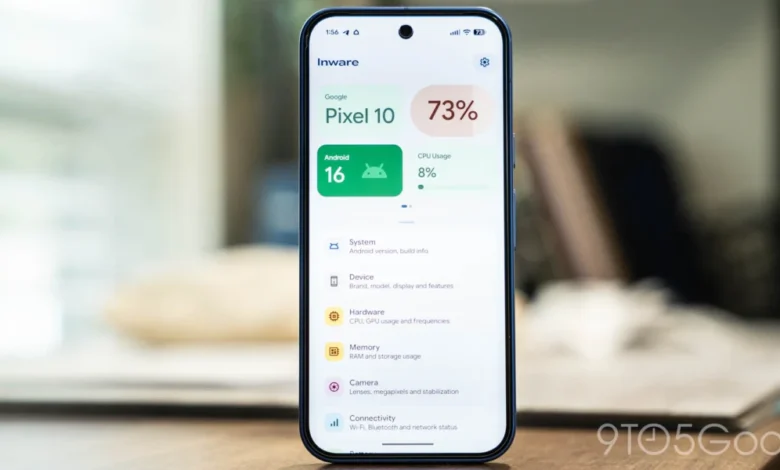
At the forefront of Inware 7.0’s update is a radical redesign that fully embraces Google’s Material 3 Expressive design language. Material Design, since its inception, has undergone several iterations, each aiming to refine the user interface and experience across the Android ecosystem. Material You, introduced with Android 12, brought dynamic theming and personalization to the forefront. Material 3, building on this, further refined components, typography, and accessibility. The "Expressive" aspect of Material 3 signifies a more dynamic, fluid, and visually engaging user interface, characterized by larger, more pronounced elements, vibrant color palettes, and a greater emphasis on intuitive user interaction. This shift aligns Inware with the cutting edge of Android’s visual paradigm, offering a fresh, modern, and highly polished user experience.
The redesign is not merely skin-deep; it fundamentally alters the app’s layout and navigational structure. Upon launching Inware 7.0, users are greeted with a more streamlined initial view, featuring a few prominent tiles at the top that highlight critical information such as battery status, real-time CPU usage, and the device’s model. This intelligent prioritization ensures that the most frequently sought data is immediately accessible, reducing clutter and enhancing usability for quick checks. The remaining, more granular details are now meticulously organized within a series of intuitive menus underneath these primary tiles, maintaining depth without sacrificing ease of navigation. This hierarchical organization reflects a thoughtful approach to information architecture, balancing immediate visibility with comprehensive access.
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://9to5google.com/wp-content/uploads/sites/4/2026/04/inware-7.jpg?quality=82&strip=all&w=1600)
Further contributing to the sophisticated aesthetic is the widespread integration of the Google Sans Flex font. Google Sans Flex is a variable font designed by Google, known for its clean lines, modern appearance, and versatility across different weights and styles. Its adoption throughout Inware 7.0 provides a consistent and premium typographic experience, enhancing readability and contributing to the app’s overall polished feel. Complementing this visual finesse are "more animations," which introduce a layer of fluidity and responsiveness to the user interface. These subtle yet impactful animations improve the user experience by providing visual feedback for interactions, making transitions smoother, and lending a dynamic, engaging quality to the app’s operation. This commitment to detailed animation work underscores the developer’s dedication to creating a truly delightful user experience, moving beyond mere functionality to offer an engaging interaction.
Advanced Diagnostics: Unpacking the New Feature Set
The functional enhancements in Inware 7.0 provide significant value for both technical enthusiasts and average users looking to optimize their device’s performance and longevity.
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://9to5google.com/wp-content/uploads/sites/4/2026/04/Screenshot_20260420-135134.png?w=456)
Active Thermal Throttling Monitoring: Thermal throttling is a critical mechanism employed by modern processors (CPUs and GPUs) to prevent overheating. When a device’s internal temperature reaches a predefined threshold, the system automatically reduces the processor’s clock speed and power consumption to dissipate heat and prevent potential hardware damage. While essential for device protection, thermal throttling can lead to noticeable performance degradation, manifesting as slower app responsiveness, reduced frame rates in games, or sluggish multitasking. Inware 7.0’s ability to display active thermal throttling allows users to immediately identify if their device is underperforming due to heat. This is invaluable for diagnosing issues during demanding tasks like gaming, video editing, or prolonged GPS navigation, helping users understand if their device is being pushed beyond its sustainable limits. Such insights can guide users in adjusting their usage patterns or identifying potential cooling issues.
6GHz Wi-Fi Detection: The introduction of Wi-Fi 6E ushered in the use of the 6GHz frequency band, offering significant advantages over the traditional 2.4GHz and 5GHz bands. The 6GHz band provides substantially higher speeds, lower latency, and dramatically less interference due to its wider spectrum and fewer legacy devices operating on it. This translates to a superior wireless experience, particularly in crowded environments. Inware 7.0’s capability to detect 6GHz Wi-Fi utilization allows users to confirm if their device is connected to a Wi-Fi 6E network and actively benefiting from its enhanced performance. This feature is crucial for users investing in new Wi-Fi 6E routers and devices, ensuring they are indeed leveraging the latest wireless technology for optimal connectivity.
Thread Connectivity: Thread is an IP-based mesh networking protocol specifically designed for smart home devices, forming the backbone of the Matter interoperability standard. Unlike Wi-Fi, which can be power-intensive, or Bluetooth, which has limited range, Thread offers a robust, self-healing, low-power mesh network that allows smart devices to communicate directly and reliably with each other, even if one device goes offline. Its benefits include enhanced reliability, reduced latency, and extended battery life for compatible devices. As the smart home ecosystem continues to grow, knowing if a smartphone supports or is actively utilizing Thread connectivity becomes increasingly relevant. Inware 7.0 provides this information, helping users confirm their device’s compatibility with the burgeoning Thread and Matter smart home landscape, which can influence purchasing decisions for smart home hubs or accessories.
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://9to5google.com/wp-content/uploads/sites/4/2026/04/Screenshot_20260420-135143.png?w=456)
Battery Cycle Count: A battery cycle refers to one full charge and discharge of a battery. Over time, as a battery accumulates charge cycles, its capacity to hold a charge gradually diminishes, a natural process of chemical degradation. Monitoring the battery cycle count provides a far more accurate assessment of a battery’s actual health and degradation level than a simple percentage indicator. While a phone might show 100% charge, a high cycle count could indicate a significantly reduced actual capacity. Inware 7.0’s integration of this metric empowers users to understand the true state of their device’s battery health, helping them predict when a replacement might be necessary, assess the longevity of their device, or even factor into the resale value of a used smartphone. This deep dive into battery health offers crucial long-term insights for device management.
Under the Hood: A Rewired Foundation
The developer’s note stating that the app has been "rewired top to bottom" and "bugs squashed" signifies a monumental effort beyond the visible changes. Migrating an application to a new design language like Material 3 Expressive often entails rewriting significant portions of the user interface code, updating dependencies, and ensuring compatibility across a vast array of Android devices and versions. This is particularly challenging in the fragmented Android ecosystem, where hardware variations can make consistent data extraction and display complex.
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://9to5google.com/wp-content/uploads/sites/4/2026/04/Screenshot_20260420-135153.png?w=456)
The underlying architecture of Inware likely had to be refactored to support the new features, ensuring accurate and real-time data collection from various system APIs. This "rewiring" suggests a commitment to improving the app’s stability, efficiency, and future extensibility. Furthermore, the mention of updated language translations indicates an ongoing dedication to global accessibility, making this powerful tool available to a wider international audience. Such extensive development work highlights the continuous investment in making Inware a reliable and state-of-the-art utility.
Broader Impact and Implications
The Inware 7.0 update carries significant implications for various stakeholders within the Android ecosystem:
![Inware now tells you even more about your Android device with expressive makeover [Gallery]](https://9to5google.com/wp-content/uploads/sites/4/2026/04/Screenshot_20260420-135215.png?w=456)
For End-Users: The most immediate beneficiaries are the users. With Inware 7.0, they gain access to a more visually appealing, intuitive, and feature-rich application. The enhanced diagnostic capabilities empower them to better understand, troubleshoot, and manage their Android devices. This transparency can lead to more informed purchasing decisions (e.g., verifying Wi-Fi 6E or Thread support), better device maintenance practices (e.g., monitoring battery health), and a deeper appreciation for their device’s technical specifications. It demystifies aspects of smartphone operation that were once obscure, transforming users from passive consumers to active participants in their device’s lifecycle.
For Developers and the Android Ecosystem: Inware 7.0 serves as an excellent showcase for Google’s Material 3 Expressive design language. Its successful implementation demonstrates how modern design principles can be applied to utility applications, setting a high standard for other developers. By adopting Google Sans Flex and emphasizing fluid animations, Inware contributes to the overall aesthetic coherence of the Android platform. Furthermore, by actively supporting and reporting on new technologies like 6GHz Wi-Fi and Thread, Inware helps drive awareness and adoption of these standards, contributing to a more advanced and interconnected Android ecosystem. The "rewiring" also implies best practices in modern Android development, potentially inspiring other developers to refine their application architectures.
For Device Manufacturers: While not directly impacting manufacturers, apps like Inware indirectly influence consumer expectations. As users become more aware of specific hardware capabilities and performance metrics, they may increasingly demand these features from new devices. The ability to monitor thermal throttling, for instance, could highlight devices with superior cooling solutions, thereby subtly influencing market trends towards better-engineered hardware.
Looking Ahead
The release of Inware 7.0 is not merely an incremental update; it represents a significant leap forward for device information applications on Android. By meticulously blending cutting-edge design with powerful new diagnostic capabilities, Inware has set a new benchmark for what users can expect from such utilities. The commitment to a fluid, informative, and aesthetically pleasing user experience, coupled with the introduction of critical new data points, positions Inware as an indispensable tool in the evolving landscape of Android technology. As smart devices become more complex and integrated into daily life, applications that provide clear, actionable insights into their operation will only grow in importance. Inware 7.0 is a testament to this necessity, offering a sophisticated and user-friendly portal into the intricate world of Android hardware and software.








{kind=link}