
DiffusionGemma: 4x Faster Text Generation Arrives, Revolutionizing Local AI Workflows
Google has unveiled DiffusionGemma, an experimental open model poised to significantly accelerate text generation, offering up to four times faster inference speeds on dedicated GPUs. This breakthrough technology departs from traditional sequential token-by-token generation, instead employing a novel diffusion-based approach that processes entire blocks of text simultaneously. Released under an Apache 2.0 license, this 26 billion parameter Mixture of Experts (MoE) model promises to unlock new possibilities for speed-critical, interactive local AI workflows, including in-line editing and rapid prototyping.
The introduction of DiffusionGemma marks a significant evolutionary step in Large Language Model (LLM) architecture. For years, the AI research community has explored diffusion models, primarily in the realm of image generation, where they excel at creating high-fidelity visuals by progressively refining noise into coherent images. Applying this methodology to text generation, however, has presented unique challenges. Traditional autoregressive LLMs, like the widely adopted Gemma 4 family, function akin to a typewriter, generating text one word or token at a time in a linear fashion. While this approach is highly effective for cloud-based deployments where vast numbers of requests can be batched to amortize computational costs, it can lead to underutilization of hardware when running locally for a single user. The inherent sequential nature means that processing power often sits idle, waiting for the next token to be generated.
DiffusionGemma fundamentally rethinks this paradigm. Instead of predicting words sequentially, it generates an entire 256-token paragraph in a single, parallel operation. This shift from a sequential to a parallel processing model dramatically enhances hardware utilization, transforming the inference process from a slow, single-stroke typewriter to a high-speed printing press capable of outputting entire blocks of text at once. This architectural innovation is built upon the robust intelligence of the Gemma 4 family and incorporates cutting-edge research from Google DeepMind’s Gemini Diffusion project.
The implications of this speed enhancement are profound, particularly for developers and researchers focused on interactive and real-time AI applications. The latency inherent in local inference has long been a bottleneck for building responsive user experiences. DiffusionGemma directly addresses this challenge, offering a viable solution for scenarios where immediate feedback and rapid iteration are paramount.
Unlocking New Value for Developers and Researchers

The primary beneficiaries of DiffusionGemma are expected to be those working on applications that demand low latency and high interactivity. This includes:
- In-line Editing and Content Creation: Imagine an AI assistant that can suggest and implement edits within a document in near real-time, or assist in drafting content with unparalleled speed and fluidity. DiffusionGemma’s ability to process larger chunks of text simultaneously allows for more natural and responsive editing experiences.
- Rapid Prototyping and Iteration: Developers can significantly accelerate their experimentation cycles. Testing new prompts, refining model outputs, and iterating on application logic becomes a much faster and more efficient process.
- Generation of Non-Linear Text Structures: Tasks that are traditionally challenging for autoregressive models, such as generating complex code snippets with precise formatting or understanding and completing intricate markdown structures, become more manageable with DiffusionGemma’s bi-directional attention capabilities.
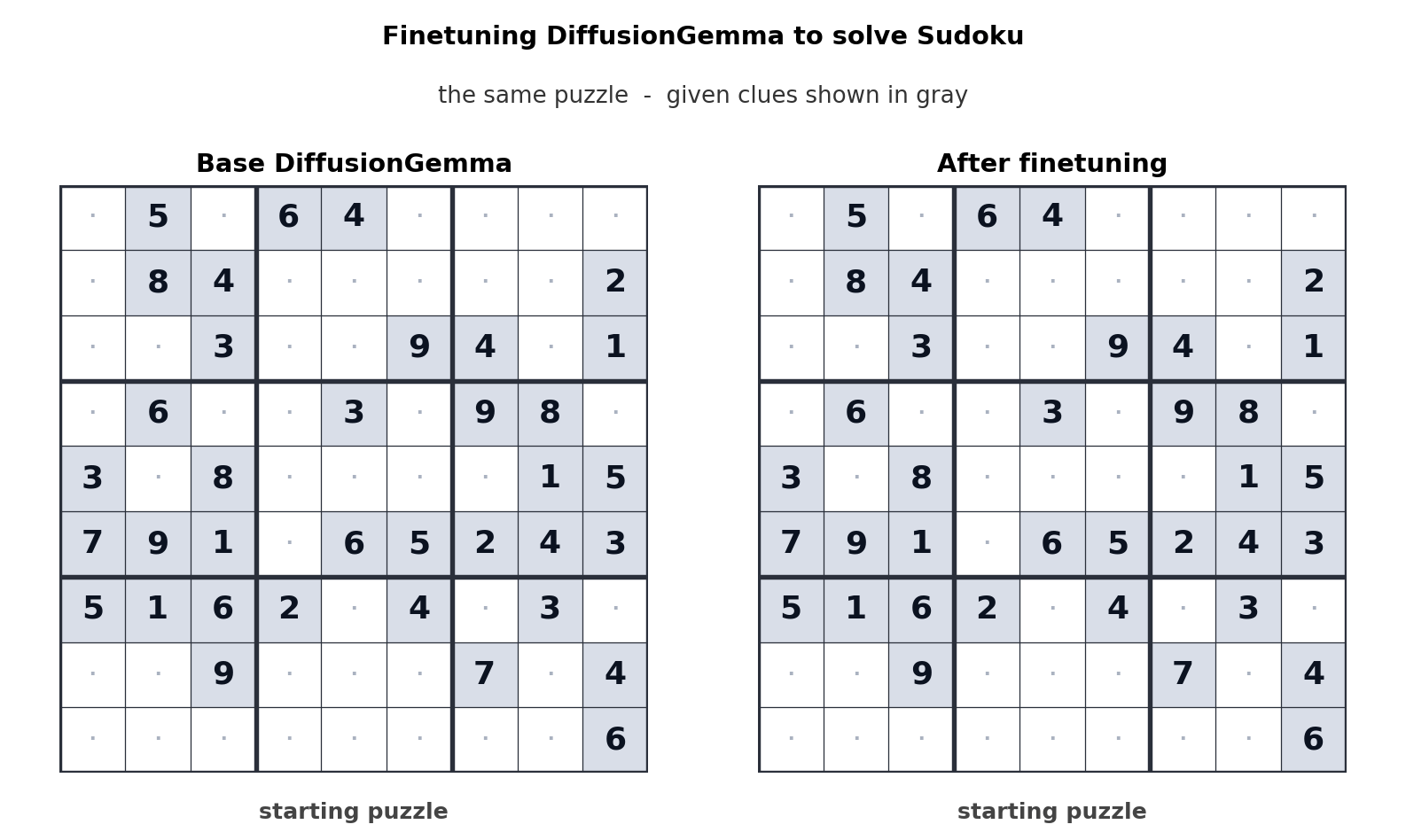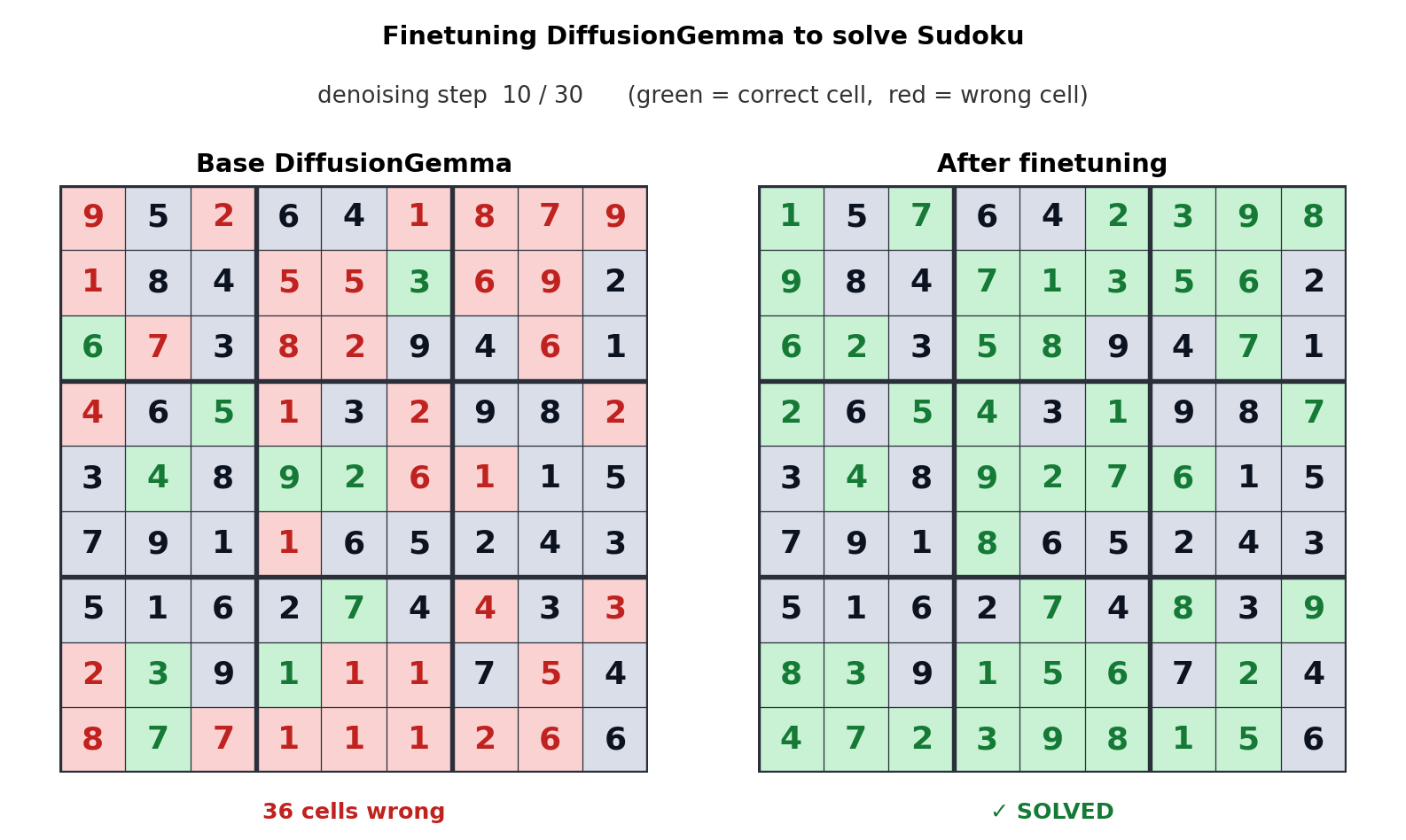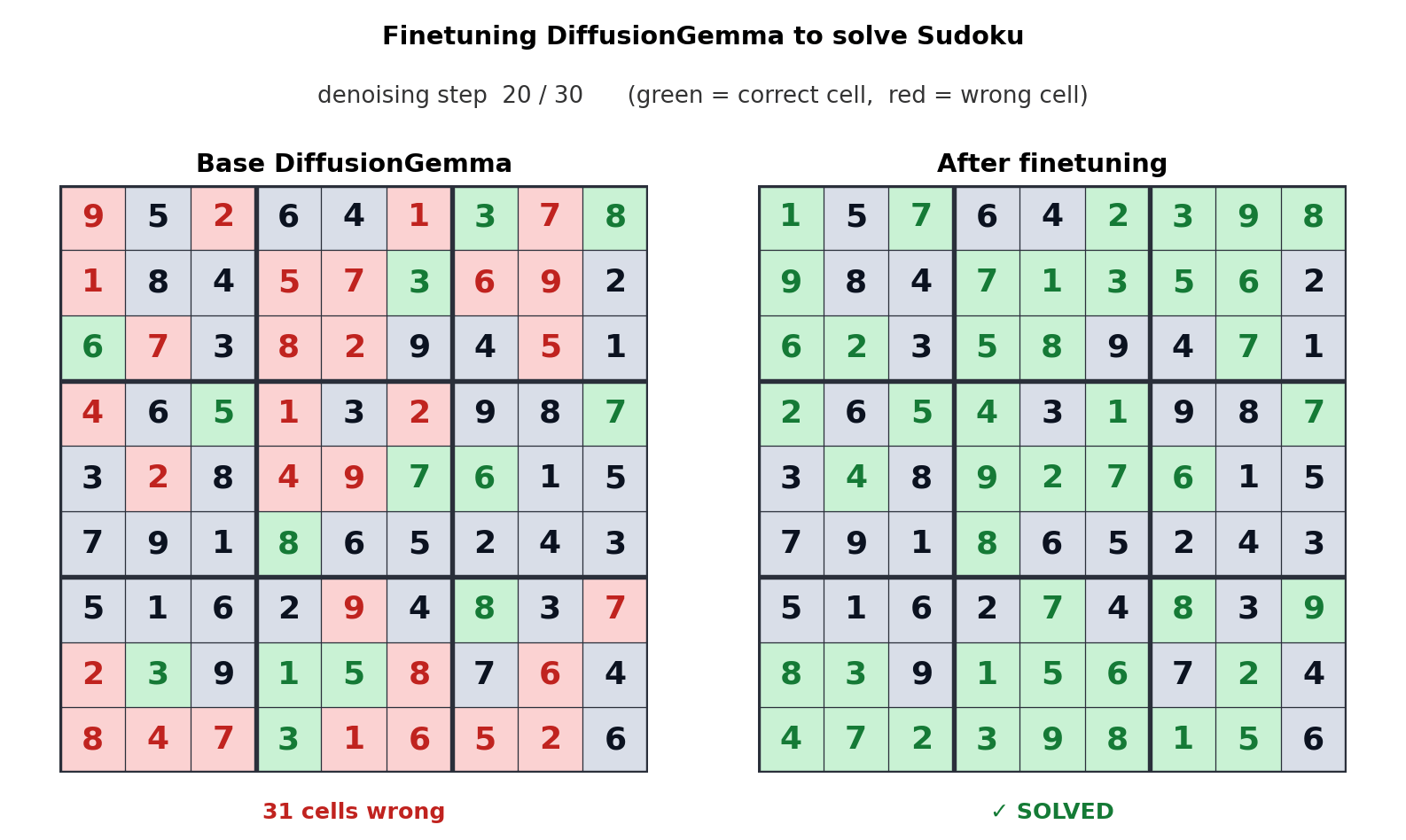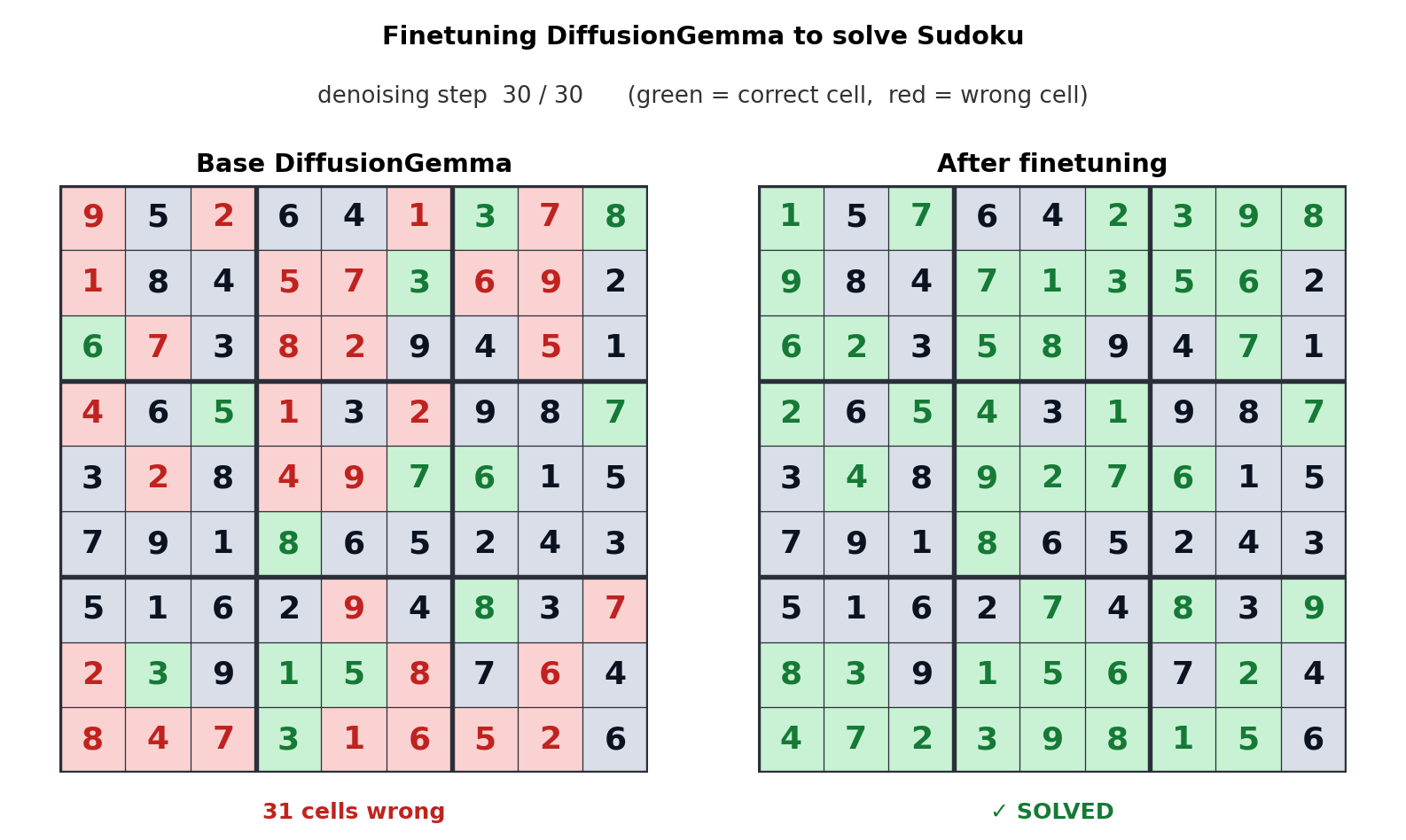
A compelling example of DiffusionGemma’s potential lies in its ability to be fine-tuned for specialized tasks. The team highlights an instance where the model was fine-tuned by Unsloth to play Sudoku. Autoregressive models often struggle with such tasks because each generated token is dependent on future tokens, creating a dependency loop that is difficult to resolve sequentially. DiffusionGemma’s parallel processing and bi-directional attention mechanism make it inherently better suited for these types of complex, interdependent generation tasks. This fine-tuning example showcases the model’s adaptability and its capacity to tackle problems that have previously been considered difficult for standard LLMs.
The Trade-Off: Local vs. Cloud Deployment
It is crucial to understand that DiffusionGemma’s speed advantage is most pronounced in specific deployment scenarios. The model is optimized for local and low-concurrency inference, where a single accelerator is dedicated to a single user or a small batch of requests. In high-throughput, high-query-per-second (QPS) cloud serving environments, traditional autoregressive models can often achieve efficient compute saturation through aggressive batching. In such scenarios, DiffusionGemma’s parallel decoding might offer diminishing returns and potentially lead to higher serving costs due to its different computational profile. Therefore, its primary value proposition lies in empowering individual users and developers with powerful AI capabilities directly on their local hardware.
The Mechanics of Text Diffusion
The core innovation of DiffusionGemma lies in its application of diffusion principles to text. Similar to how image diffusion models begin with random noise and iteratively refine it into a recognizable image, DiffusionGemma operates by generating an initial representation and then progressively enhancing it to form coherent text. This process can be visualized as follows:

- Initial Noise/Representation: The process begins with a noisy or abstract representation of the desired text output.
- Iterative Refinement: The model then applies a series of diffusion steps, gradually denoising and structuring this representation. Unlike autoregressive models that predict the next token based on previous ones, diffusion models consider the entire output space simultaneously, allowing for a more holistic generation.
- Text Generation: Through these iterative refinements, the model coalesces the representation into a complete, coherent block of text.
This methodology allows DiffusionGemma to understand and generate text with a broader context, enabling it to handle complex formatting, maintain consistency across longer passages, and even render code structures more accurately and swiftly. The parallel processing inherent in this approach means that the model can, for instance, perfectly close complex markdown formatting or generate and render code in near real-time, a feat that would typically involve multiple sequential steps for traditional models.
Background and Context
The development of DiffusionGemma emerges from a broader trend within the AI research community to explore novel architectures that can overcome the limitations of current LLMs. While autoregressive models have achieved remarkable success, their sequential nature presents inherent scaling challenges, particularly in resource-constrained environments or applications requiring instant responsiveness. Diffusion models, with their capacity for parallel processing, offer a promising alternative pathway.
Google’s prior work in diffusion models, such as their on-device diffusion plugins for text-to-image generation, has laid crucial groundwork for applying these techniques to other modalities. The Gemini Diffusion research further refined these concepts, paving the way for the integration of diffusion heads into large language models. This strategic evolution reflects Google’s commitment to pushing the boundaries of AI capabilities and making advanced models more accessible and efficient.
The release of DiffusionGemma under an open license is also a significant development. Open-sourcing models fosters collaboration, accelerates research, and democratizes access to cutting-edge AI technology. This approach encourages a wider community of developers and researchers to experiment with, build upon, and contribute to the advancement of diffusion-based text generation.
Timeline of Development (Inferred)

While specific dates for the internal development of DiffusionGemma are not publicly disclosed, its emergence can be situated within the broader timeline of advancements in diffusion models and LLMs. Research into diffusion models gained significant traction in the late 2010s and early 2020s, particularly with their success in image generation. Simultaneously, LLMs like Google’s own LaMDA and PaLM, and later the Gemma family, have demonstrated the power of large-scale autoregressive models. The Gemini family, which leverages advanced architectures, likely provided the foundational research for integrating diffusion principles into text generation. The announcement of DiffusionGemma today signifies the culmination of this research, translating theoretical breakthroughs into a practical, open-source model.
Supporting Data and Benchmarks
The core claim of DiffusionGemma is its speed advantage. The model reportedly achieves up to 4x faster text generation on dedicated GPUs. While specific benchmark figures for various hardware configurations and task complexities are still being explored and shared by the community, the provided visualizations offer a glimpse into this performance gain. One graphic, "Intelligence vs Latency," implicitly suggests a trade-off where increased intelligence (presumably of the model’s output) traditionally correlates with higher latency. DiffusionGemma aims to break this correlation by delivering high-quality output with significantly reduced latency. Another benchmark chart, "DiffusionGemma Benchmark," visually depicts the performance uplift compared to other models, likely showcasing generation speed under specific conditions. These early indicators suggest a substantial leap in efficiency for local inference tasks.
Broader Impact and Implications
The introduction of DiffusionGemma has the potential to democratize advanced AI capabilities further. By enabling faster and more efficient local inference, it empowers individuals and smaller organizations to leverage powerful language models without the need for extensive cloud infrastructure. This could lead to a surge in innovative applications and a more personalized AI experience.
Furthermore, the architectural shift towards parallel processing in text generation could inspire new avenues of research. Developers might explore hybrid models that combine the strengths of autoregressive and diffusion approaches to achieve optimal performance across diverse use cases. The open-source nature of DiffusionGemma ensures that these explorations will be conducted collaboratively, fostering a vibrant ecosystem of innovation.

The ability of DiffusionGemma to handle complex, non-linear text generation also has implications for fields requiring precise and structured output, such as scientific writing, legal documentation, and software development. As the model is further refined and adopted by the community, we can expect to see its application in increasingly sophisticated and impactful ways.
Getting Started
Google encourages developers and researchers to explore DiffusionGemma’s capabilities. The model is available under the Apache 2.0 license, making it readily accessible for experimentation and integration into new projects. Resources and documentation are being provided to guide users through the process of setting up and utilizing the model for their specific needs. The fine-tuning example with Unsloth also points to the availability of tools and frameworks that can help users adapt DiffusionGemma to specialized tasks, further enhancing its utility and broad appeal. The journey of unlocking the full potential of faster, more interactive text generation has just begun with DiffusionGemma.







{kind=link}