
Survey Results Reveal the Financial and Psychological Thresholds for Electric Vehicle Adoption Amid Rising Fuel Costs

The transition from internal combustion engine (ICE) vehicles to electric vehicles (EVs) remains one of the most debated shifts in modern industrial history, driven by a complex interplay of environmental policy, technological advancement, and consumer economics. A recent comprehensive survey conducted by the automotive news outlet Electrek has provided a granular look into the mindset of the American driver, specifically targeting the question of what fuel price point would finally trigger a mass migration to plug-in alternatives. After collecting over 2,800 responses over a seven-day period, the data suggests that for a significant portion of the population, the barrier to EV adoption is not merely a matter of dollars and cents at the pump, but a deeper entrenchment in cultural and practical preferences.
The Core Findings: A Divided Consumer Base
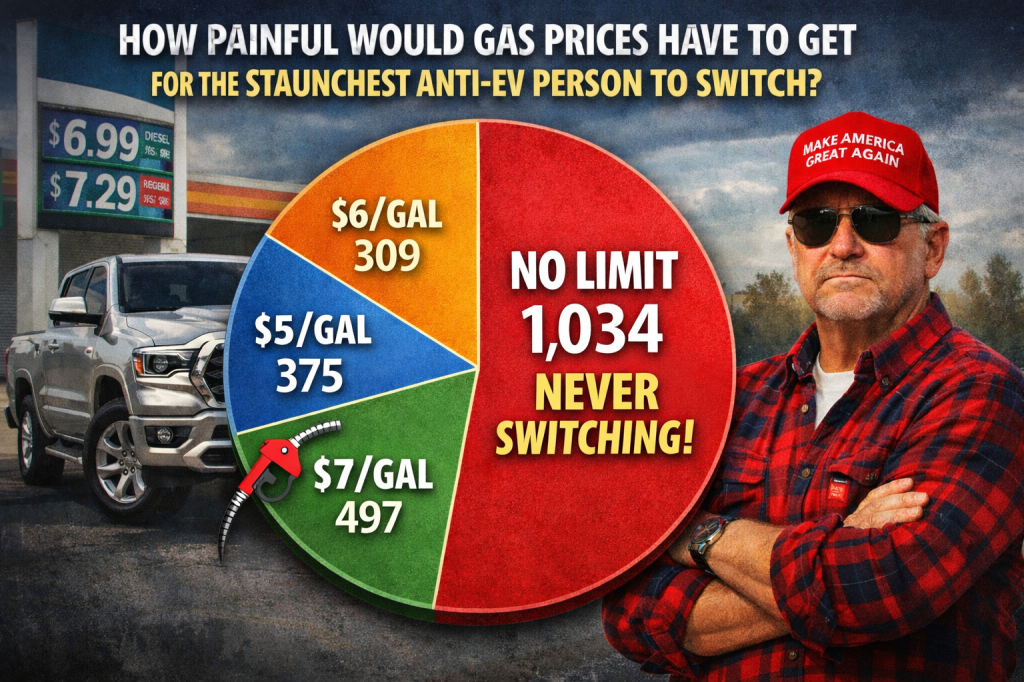
The survey asked readers to estimate the "magic number"—the price per gallon of gasoline or diesel—that would convince even the most dedicated anti-EV skeptics to make the switch. The results were polarizing. The most striking takeaway was that nearly 50% of respondents believe there is no price high enough to force a transition for certain drivers. This "ICE-only" demographic is viewed by many as being fundamentally resistant to the technology, regardless of the economic burden of fossil fuels.
For those who did believe a price threshold exists, the numbers varied significantly, with many pointing to the $10.00 per gallon mark as a psychological and financial breaking point for the average American household. However, the survey also highlighted a nuanced reality: for many consumers, the decision to switch is not based on the current price of fuel, but on the long-term outlook of energy costs and the initial capital investment required to purchase a new vehicle.

Historical Context and the Volatility of Fuel Prices
To understand these survey results, one must look at the recent history of fuel price volatility in the United States. In 2022, following the geopolitical instability caused by the invasion of Ukraine, U.S. gasoline prices hit a record national average of over $5.00 per gallon. This spike led to a measurable increase in EV interest and sales. According to data from the Alliance for Automotive Innovation, EV market share in the U.S. climbed significantly during periods of high fuel costs, suggesting that "pain at the pump" is indeed a primary catalyst for early and middle-market adopters.
However, the Electrek survey suggests that the "laggards" in the technology adoption curve—those most resistant to change—require more than just a temporary spike. For these individuals, the internal combustion engine is often tied to concerns over towing capacity, cold-weather performance, and the perceived reliability of a century-old technology compared to the relatively new infrastructure supporting EVs.
The European Benchmark: A Glimpse into High-Cost Environments
One of the most compelling arguments raised by survey participants involved comparisons with the European market. In countries like the Netherlands, fuel prices have already exceeded the equivalent of $11.00 per gallon. One respondent, Jos Hoogerwaard, noted that despite petrol prices reaching approximately $11.34 per gallon in the Netherlands, a dedicated segment of the population still refuses to switch to electric power.
In Europe, the cost of electricity is also a major factor. While charging an EV remains cheaper than fueling an ICE vehicle in most scenarios, the narrowing gap between utility rates and fuel prices can diminish the perceived savings. For example, while gas may cost $11.00 a gallon, high electricity prices in certain regions can make the "fueling" cost of an EV equivalent to $4.00 or $5.00 per gallon. For a skeptic, this marginal difference may not be enough to justify the higher upfront purchase price of an electric vehicle.

Economic Barriers: The "Paid-Off Car" Logic
A recurring theme in the survey responses was the economic logic of vehicle ownership. Many drivers, such as respondent Jacob Nelson, pointed out that the cheapest car to drive is often the one that is already paid for. Even if monthly fuel costs double from $100 to $200, that $100 increase is significantly less than a $500 to $800 monthly payment for a new electric vehicle.
This "total cost of ownership" (TCO) argument is a double-edged sword. While EVs generally have lower maintenance and fuel costs over their lifetime, the high entry price remains a barrier. According to Kelley Blue Book, the average price of a new electric vehicle in early 2024 hovered around $53,000, which is still higher than the average ICE vehicle, despite aggressive price cuts by manufacturers like Tesla and Ford. Until the used EV market matures and provides reliable options in the $15,000 to $25,000 range, the "stubborn" ICE driver may simply be making a pragmatic financial decision based on immediate cash flow rather than long-term savings.
The Role of Energy Independence and Home Infrastructure
The survey also touched upon a unique advantage of electric vehicles that is often overlooked in the "gas vs. electricity" price debate: the ability to generate one’s own fuel. Proponents of EVs, including industry experts like Jim Reilly of GM Energy, argue that the transition is about "energy dominance." By combining an EV with home solar panels and battery storage, a homeowner effectively becomes their own "refinery."
This shift from being a consumer of a volatile commodity (oil) to a producer of energy (solar) represents a fundamental change in the relationship between the driver and their vehicle. For those who have made the switch, the rising cost of gasoline is irrelevant. However, the survey suggests that this level of "imagination" or long-term planning has not yet permeated the mindset of the general public, many of whom live in apartments or rental properties where home charging and solar installations are not currently feasible.
Psychological and Cultural Resistance
Beyond the numbers, the survey highlights a significant cultural divide. For many, the choice of vehicle is an expression of identity. The term "anti-EV hysteric," used in the survey prompt, reflects the intense polarization surrounding the topic. This group often cites "range anxiety" and "charging infrastructure" as primary concerns, but analysts suggest these are often proxies for a general discomfort with rapid technological and societal change.
The "stubbornness" identified by Electrek readers may also be fueled by misinformation regarding battery longevity and the environmental impact of lithium mining. While studies from organizations like the International Energy Agency (IEA) show that EVs have a significantly lower lifecycle carbon footprint than ICE vehicles, the counter-narratives remain prevalent in social media and certain political circles, reinforcing the resolve of those who refuse to switch.
Implications for Policy and the Automotive Industry
The results of this survey have broader implications for both policymakers and automotive manufacturers. If nearly half of the holdouts cannot be swayed by fuel prices alone, then government mandates—such as those in California and the European Union aiming to phase out the sale of new ICE vehicles by 2035—may face continued political and social pushback.
For manufacturers, the data suggests that marketing efforts focusing solely on "saving money at the pump" may have reached their limit. To capture the remaining segments of the market, the industry may need to focus on:

- Price Parity: Bringing the initial purchase price of EVs down to match or beat ICE equivalents without relying on federal tax credits.
- Infrastructure Ubiquity: Ensuring that charging is as fast and convenient as a five-minute stop at a gas station, particularly for those without home charging.
- Versatility: Developing electric versions of the vehicles that skeptics rely on, such as heavy-duty trucks and rugged off-road vehicles, that do not compromise on performance.
Timeline of the EV Transition
To put the survey in context, the timeline of the EV transition has moved through several distinct phases:
- 2010–2015: The "Innovator" phase, dominated by the Tesla Roadster and early Nissan Leaf. Buyers were primarily tech enthusiasts and environmentalists.
- 2016–2021: The "Early Adopter" phase, characterized by the launch of the Tesla Model 3 and the expansion of the Supercharger network.
- 2022–Present: The "Early Majority" phase, where major legacy automakers (GM, Ford, VW, Hyundai) have entered the market with diverse offerings. This is the stage where fuel price spikes began to drive mass interest.
- 2025–2030 (Projected): The "Late Majority" phase, where the success of the transition will depend on the used car market and the stabilization of charging infrastructure.
Final Analysis: Is There a Breaking Point?
The Electrek survey underscores a sobering reality for the green energy transition: economics is a powerful motivator, but it is not the only one. While a $10.00 gallon of gas would undoubtedly push millions toward electric mobility, there remains a "hard core" of drivers for whom the internal combustion engine is a non-negotiable preference.
Whether this resistance is driven by genuine practical needs, financial constraints regarding new vehicle purchases, or a cultural attachment to the roar of an engine, it represents a significant hurdle for the goal of total electrification. As the automotive landscape continues to evolve, the industry must address these nuanced concerns—moving beyond the price of fuel to address the total experience of vehicle ownership, reliability, and the democratization of home energy. The next phase of the transition may not be won at the pump, but in the showroom and the court of public opinion.






{kind=link}