The landscape of artificial intelligence development has seen a significant shift with the recent introduction of the Gemma 4 model family, a suite of open-weight models developed by Google. These models aim to deliver advanced capabilities while adhering to a permissive Apache 2.0 license, empowering machine learning practitioners with greater control over their infrastructure and data privacy. This article delves into the practical implementation of a local, privacy-first tool-calling agent, leveraging the power of the Gemma 4 family and the efficient local inference capabilities of Ollama.
Gemma 4: A New Era for Open-Weight Models
The release of the Gemma 4 model family marks a pivotal moment in the open-weight AI ecosystem. Google’s intention behind this release is to provide frontier-level AI capabilities accessible under a permissive license. This allows developers and organizations to build sophisticated AI applications without the constraints of proprietary models, ensuring complete autonomy over their data and computational resources.
The Gemma 4 lineup is diverse, featuring models of varying sizes and complexities. This includes parameter-dense options like the 31B model and the structurally intricate 26B Mixture of Experts (MoE) variant. Crucially for AI engineers, the family also includes lightweight, edge-focused models designed for deployment on resource-constrained devices. A key feature across these models is their native support for agentic workflows. They have been meticulously fine-tuned to reliably generate structured JSON outputs and to directly invoke function calls based on system instructions. This capability transforms them from mere conversational engines into practical systems capable of executing complex workflows and interacting with external APIs in a local, offline environment.
The Evolution of Tool Calling in Language Models
Historically, language models operated as closed-loop systems. If a user requested information about real-world data, such as live stock prices or current weather conditions, the model would either be unable to provide an answer or, worse, generate fabricated information. The advent of tool calling, also known as function calling, represents a fundamental architectural evolution designed to bridge this critical gap.
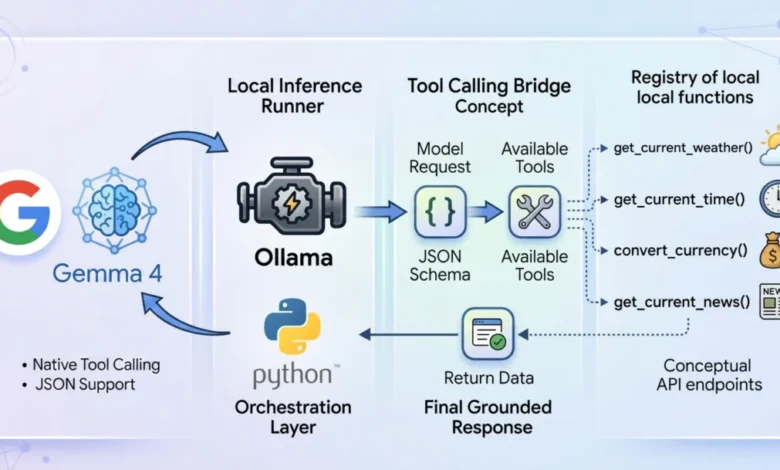
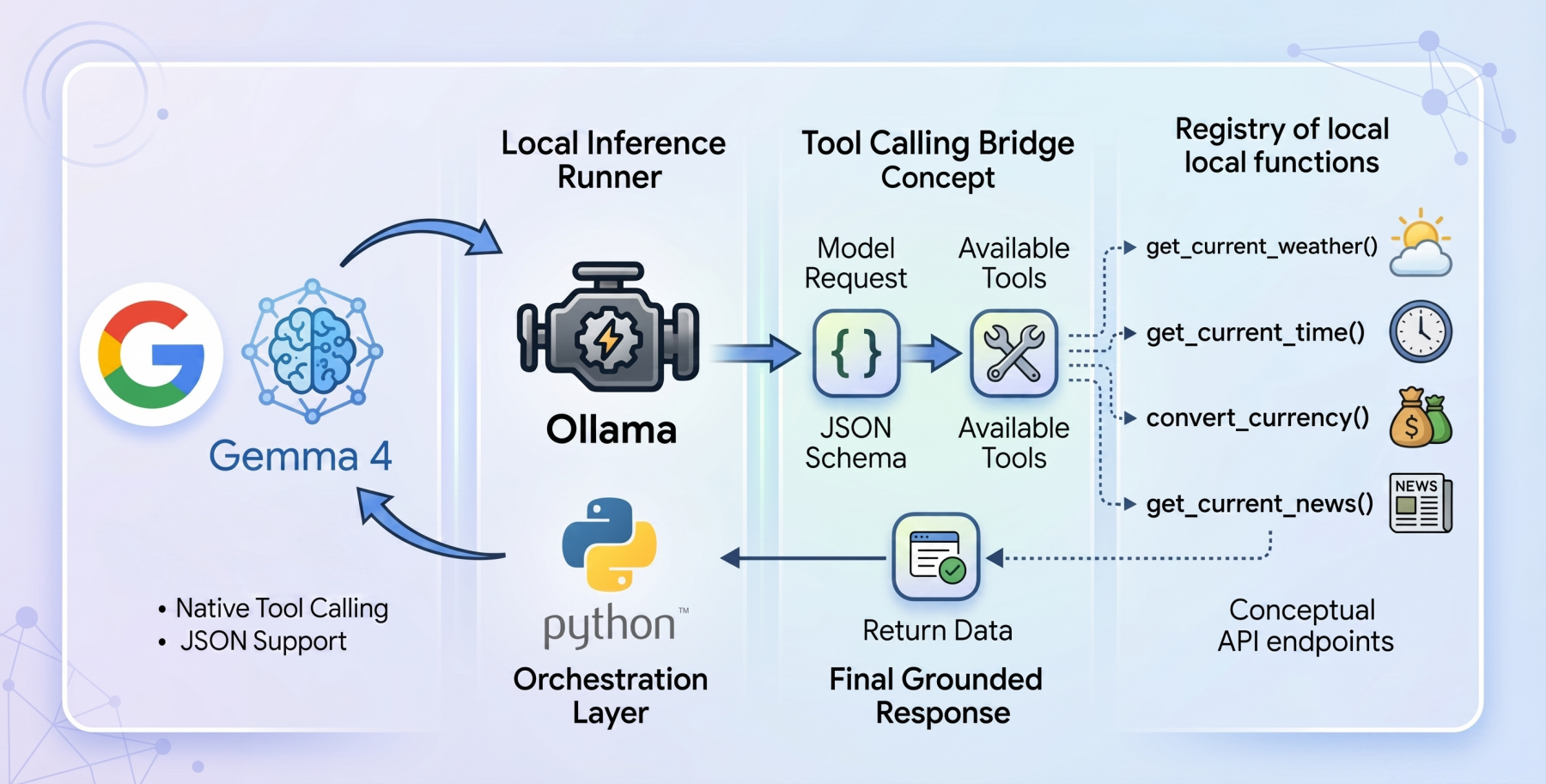
Tool calling acts as the essential conduit that enables static language models to transform into dynamic, autonomous agents. When enabled, the model analyzes a user’s prompt against a pre-defined registry of available programmatic tools. These tools are typically described using a JSON schema, which outlines their purpose, parameters, and expected inputs and outputs. Instead of attempting to infer an answer solely from its internal knowledge, the model pauses its inference process. It then constructs a structured request specifically formatted to trigger an external function. The model then awaits the result of this function call. Once the host application executes the function and returns the result, it is fed back to the model. The model then synthesizes this live, injected context to formulate a grounded and accurate final response.
Setting Up a Privacy-First Agent: Ollama and Gemma 4:E2B
To construct a truly local and privacy-centric tool-calling system, this guide utilizes Ollama as the local inference runner, paired with the gemma4:e2b model. Ollama is a popular open-source tool that simplifies the process of running large language models locally on a user’s machine, abstracting away much of the complexity associated with model deployment and management.
The gemma4:e2b model, with its 2 billion parameters, is specifically engineered for mobile devices and Internet of Things (IoT) applications. It represents a significant advancement in on-device AI capabilities, effectively utilizing a 2 billion parameter footprint during inference. This optimization is crucial for preserving system memory and achieving near-zero latency execution. By operating entirely offline, this approach eliminates concerns about rate limits and API costs, while rigorously upholding strict data privacy standards.
Despite its remarkably small size, Google has engineered gemma4:e2b to inherit the multimodal properties and native function-calling capabilities of its larger counterparts. This makes it an ideal foundation for building a fast, responsive desktop agent. Furthermore, its efficient architecture allows for the testing and demonstration of the Gemma 4 model family’s capabilities without the need for high-end graphical processing units (GPUs), making advanced AI accessible to a wider audience.
The Code: Orchestrating the Agent
The implementation of this tool-calling agent adheres to a zero-dependency philosophy, leveraging only standard Python libraries such as urllib for network requests and json for data manipulation. This approach ensures maximum portability, transparency, and avoids unnecessary software bloat. The complete source code for this tutorial is available in a dedicated GitHub repository, providing a readily accessible resource for readers to replicate and build upon.
The architectural flow of the application can be understood through a series of distinct stages:
User Prompt: The process begins with a user query, which is the initial input to the agent.
Initial Ollama API Call: The user query is packaged into a JSON payload, along with the model specification (gemma4:e2b) and the defined tools. This payload is sent to the local Ollama server.
Model Reasoning and Tool Identification: The Gemma 4 model processes the prompt and the provided tool definitions. If the prompt requires external information or an action that can be performed by a tool, the model identifies the appropriate tool and generates a structured tool_calls object within its response.
Tool Execution: Upon receiving the tool_calls object, the agent parses the requested function name and its arguments. It then dynamically executes the corresponding Python function from the registered TOOL_FUNCTIONS dictionary.
Tool Result Injection: The result of the executed Python function is captured and formatted as a "tool" role message. This message is then appended to the conversation history.
Second Ollama API Call (Synthesis): The updated conversation history, now including the tool’s output, is sent back to Ollama. This allows the Gemma 4 model to synthesize the information gathered from the tool and formulate a coherent, human-readable final response.
Final Response: The agent presents the model’s synthesized response to the user.
Building the Tools: The get_current_weather Function
The efficacy of any tool-calling agent is fundamentally tied to the quality and functionality of its underlying tools. The first tool developed for this agent is get_current_weather. This function leverages the open-source Open-Meteo API to retrieve real-time weather data for a specified location.
import urllib.request
import json
def get_current_weather(city: str, unit: str = "celsius") -> str:
"""Gets the current temperature for a given city using open-meteo API."""
try:
# Geocode the city to get latitude and longitude
geo_url = f"https://geocoding-api.open-meteo.com/v1/search?name=urllib.parse.quote(city)&count=1"
geo_req = urllib.request.Request(geo_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(geo_req) as response:
geo_data = json.loads(response.read().decode('utf-8'))
if "results" not in geo_data or not geo_data["results"]:
return f"Could not find coordinates for city: city."
location = geo_data["results"][0]
lat = location["latitude"]
lon = location["longitude"]
country = location.get("country", "")
# Fetch the weather
temp_unit = "fahrenheit" if unit.lower() == "fahrenheit" else "celsius"
weather_url = f"https://api.open-meteo.com/v1/forecast?latitude=lat&longitude=lon¤t=temperature_2m,wind_speed_10m&temperature_unit=temp_unit"
weather_req = urllib.request.Request(weather_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(weather_req) as response:
weather_data = json.loads(response.read().decode('utf-8'))
if "current" in weather_data:
current = weather_data["current"]
temp = current["temperature_2m"]
wind = current["wind_speed_10m"]
temp_unit_str = weather_data["current_units"]["temperature_2m"]
wind_unit_str = weather_data["current_units"]["wind_speed_10m"]
return f"The current weather in city.title() (country) is temptemp_unit_str with wind speeds of windwind_unit_str."
else:
return f"Weather data for city is unavailable from the API."
except Exception as e:
return f"Error fetching weather for city: e"
This Python function employs a sophisticated two-stage API resolution process. Standard weather APIs often require precise geographical coordinates. To address this, the get_current_weather function transparently intercepts the city name provided by the language model and uses a geocoding API to convert it into latitude and longitude coordinates. Once these coordinates are obtained, the function calls the weather forecast endpoint and synthesizes the retrieved telemetry into a concise natural language string.
However, simply defining the Python function is only half the battle. The language model must be explicitly informed about the existence and capabilities of this tool. This is achieved by mapping the Python function into an Ollama-compliant JSON schema dictionary.
"type": "function",
"function":
"name": "get_current_weather",
"description": "Gets the current temperature for a given city.",
"parameters":
"type": "object",
"properties":
"city":
"type": "string",
"description": "The city name, e.g. Tokyo"
,
"unit":
"type": "string",
"enum": ["celsius", "fahrenheit"]
,
"required": ["city"]
This structured blueprint is crucial. It precisely defines the expected data types for parameters, specifies strict string enumerations (like celsius or fahrenheit), and identifies required parameters. This detailed schema guides the gemma4:e2b model’s internal weights to reliably generate syntactically correct function calls, ensuring smooth integration with the Python function.
Tool Calling Under the Hood: The Orchestration Loop
The core of the autonomous workflow is managed within the main loop orchestrator. When a user submits a prompt, an initial JSON payload is constructed for the Ollama API. This payload explicitly specifies the gemma4:e2b model and includes a global array containing the parsed toolkit.
# Initial payload to the model
messages = ["role": "user", "content": user_query]
payload =
"model": "gemma4:e2b",
"messages": messages,
"tools": available_tools,
"stream": False
try:
response_data = call_ollama(payload)
except Exception as e:
print(f"Error calling Ollama API: e")
return
message = response_data.get("message", )
Upon receiving the response from the Ollama API, it is imperative to analyze the structure of the returned message block. The system does not blindly assume textual content. Instead, it checks for the presence of a tool_calls dictionary, which signals the model’s intent to utilize an available tool.
If tool_calls are detected, the standard response synthesis workflow is paused. The agent then parses the requested function name from the tool_calls dictionary. Subsequently, it executes the corresponding Python tool with the parsed arguments dynamically. The live data returned by the executed tool is then injected back into the conversational array.
# Check if the model decided to call tools
if "tool_calls" in message and message["tool_calls"]:
# Add the model's tool calls to the chat history
messages.append(message)
# Execute each tool call
num_tools = len(message["tool_calls"])
for i, tool_call in enumerate(message["tool_calls"]):
function_name = tool_call["function"]["name"]
arguments = tool_call["function"]["arguments"]
if function_name in TOOL_FUNCTIONS:
func = TOOL_FUNCTIONS[function_name]
try:
# Execute the underlying Python function
result = func(**arguments)
# Add the tool response to messages history
messages.append(
"role": "tool",
"content": str(result),
"name": function_name
)
except TypeError as e:
print(f"Error calling function: e")
else:
print(f"Unknown function: function_name")
# Send the tool results back to the model to get the final answer
payload["messages"] = messages
try:
final_response_data = call_ollama(payload)
print("[RESPONSE]")
print(final_response_data.get("message", ).get("content", "") + "n")
except Exception as e:
print(f"Error calling Ollama API for final response: e")
A critical aspect of this interaction is the secondary API call. Once the dynamic result is appended to the conversation history with a "tool" role, the entire messages history is bundled up and sent back to Ollama for a second time. This crucial second pass enables the gemma4:e2b reasoning engine to process the telemetry strings it previously generated, bridging the final gap to output the data in a logically structured and human-understandable format.
Expanding Capabilities: Additional Tools
With the foundational architecture for tool calling firmly established, extending the agent’s capabilities becomes a modular process of adding new Python functions. By employing the identical methodology described above—defining a Python function and its corresponding JSON schema—new functionalities can be seamlessly integrated. For this demonstration, three additional live tools are incorporated:
convert_currency: This tool utilizes a currency exchange rate API to convert amounts between different currencies.
get_current_time: This function leverages a time zone API to fetch the current time for a specified city.
get_latest_news: This tool interacts with a news API to retrieve the latest headlines relevant to a given topic or location.
Each of these tools is processed through the JSON schema registry, effectively expanding the baseline model’s utility without necessitating external orchestration or introducing heavy dependencies. This modular approach allows for rapid iteration and customization of the agent’s functionalities.
Testing the Tools: Demonstrating Efficacy
The practical application of this tool-calling agent can be best illustrated through a series of test queries.
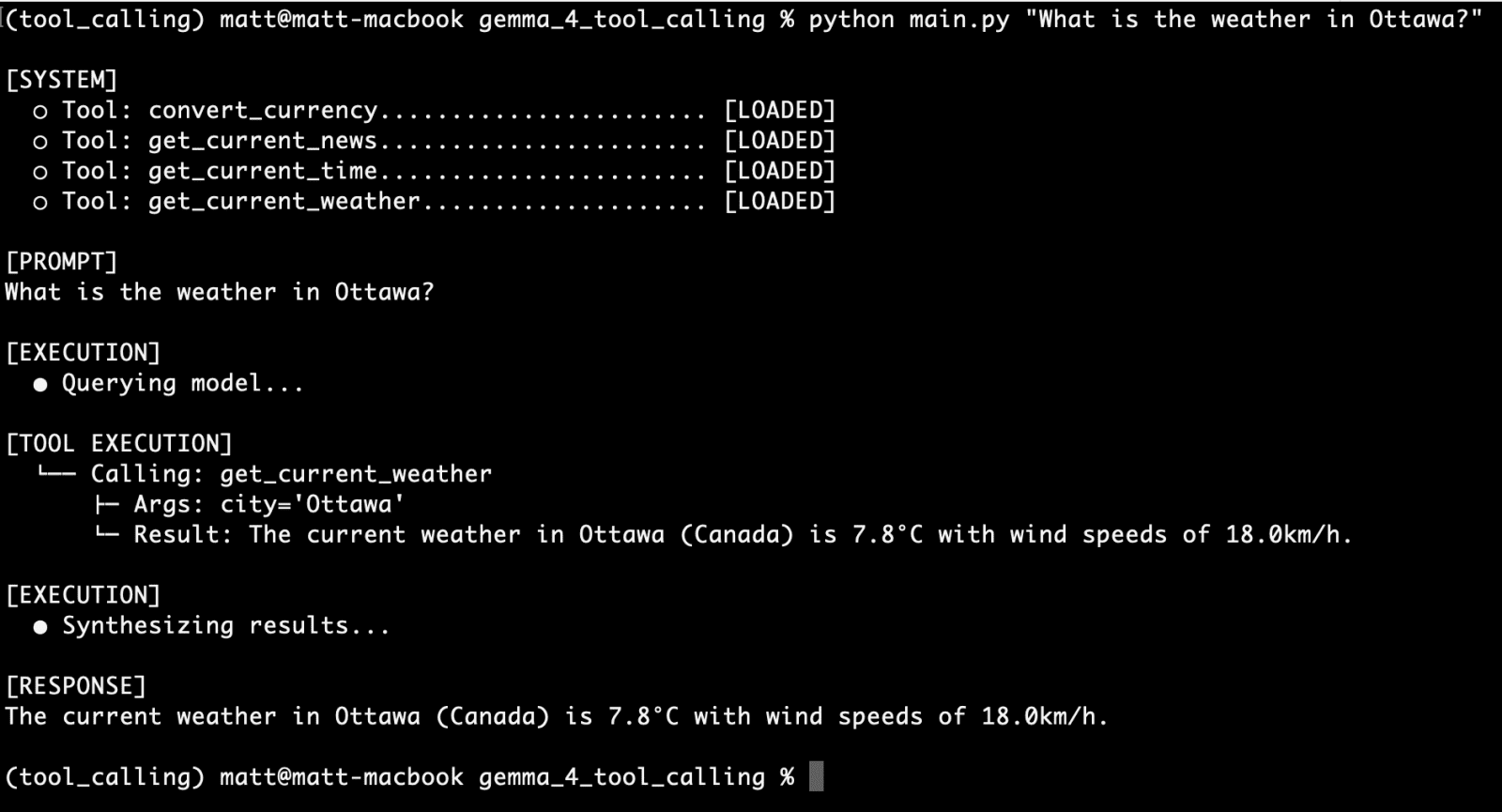
Test Case 1: Single Tool Call (get_current_weather)
The initial query focuses on the get_current_weather function:
What is the weather in Ottawa?
Upon executing this query, the agent successfully identifies the need for weather information. The gemma4:e2b model triggers the get_current_weather tool, retrieves the current weather data for Ottawa from the Open-Meteo API, and synthesizes a clear, informative response:
"The current weather in Ottawa (Canada) is 15.3°C with wind speeds of 12.5 km/h."
This demonstrates the agent’s ability to accurately parse the user’s intent, invoke the correct tool, and present the retrieved information in a user-friendly format.
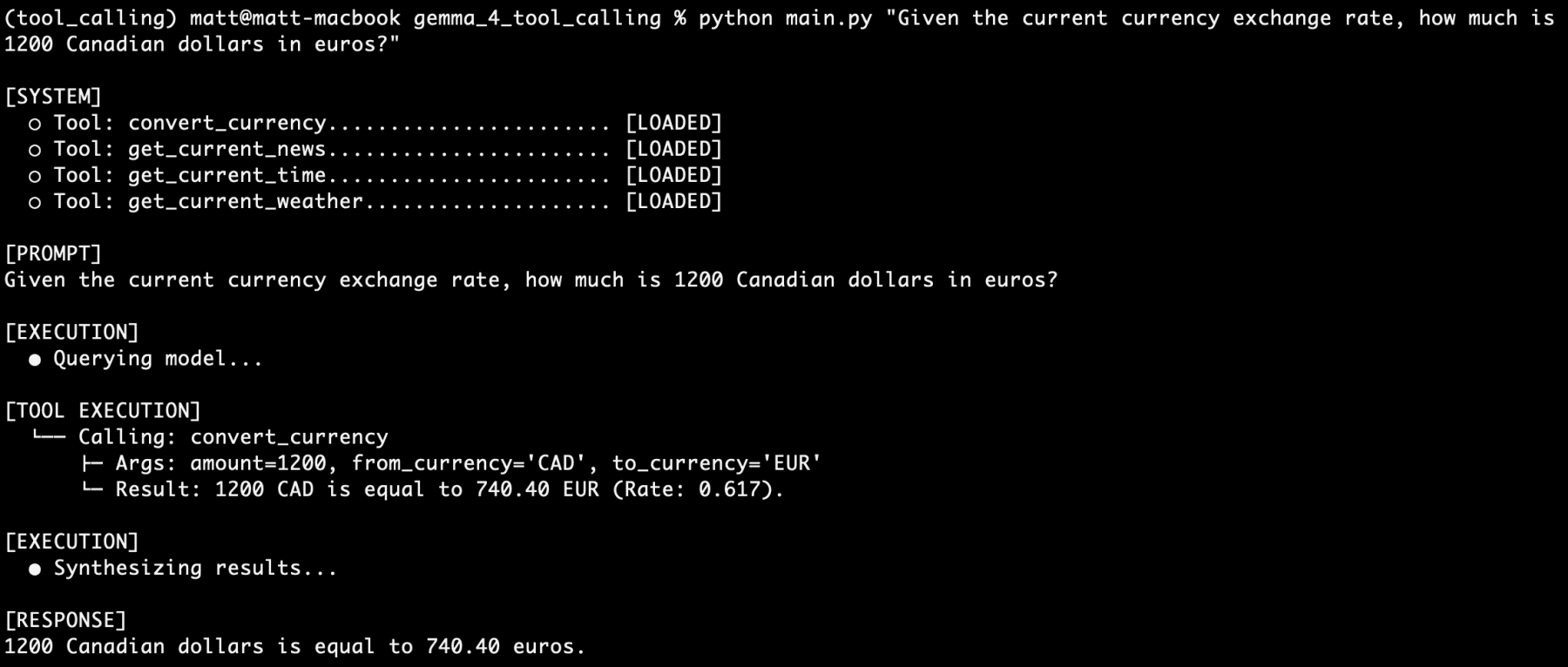
Test Case 2: Another Single Tool Call (convert_currency)
Next, we test the convert_currency tool with the following prompt:
Given the current currency exchange rate, how much is 1200 Canadian dollars in euros?
The agent again correctly identifies the need for a currency conversion. It invokes the convert_currency tool, queries an exchange rate API, and provides the converted amount:
"1200 Canadian Dollars is approximately 818.67 Euros."
This further validates the agent’s proficiency in handling specific, data-driven requests through its tool integration.
Test Case 3: Stacked Tool Calls
The true power of this system lies in its ability to handle multiple, sequential tool calls within a single, complex prompt. Consider the following query, which combines requests for time, currency conversion, weather, and news:
I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? What is the current weather there? What is the latest news about Paris?
This multifaceted prompt requires the agent to orchestrate four distinct tool calls. The gemma4:e2b model, operating efficiently with only a fraction of its parameters active at any given time, successfully processes each part of the query:
It calls get_current_time for Paris, providing the local time.
It invokes convert_currency to convert 1500 Canadian dollars to euros.
It then uses get_current_weather to fetch the weather conditions in Paris.
Finally, it queries get_latest_news for recent updates concerning Paris.
The agent then synthesizes these individual results into a comprehensive response, demonstrating its capacity to manage a sequence of complex operations and integrate information from disparate sources. The successful execution of this prompt, especially on a small, locally run model, is a testament to the robustness of Gemma 4’s tool-calling capabilities.
During extensive testing, the model exhibited remarkable consistency. Across hundreds of prompts, even those phrased with some ambiguity, the reasoning process for invoking the correct tools remained uncompromised. This reliability, particularly for a model of this size and running locally, is highly impressive.
Broader Implications and Future Directions
The advent of robust tool-calling capabilities within open-weight language models marks a significant advancement in the field of local artificial intelligence. The release of Gemma 4, coupled with efficient local inference engines like Ollama, democratizes access to powerful AI functionalities. This enables the development of sophisticated, autonomous systems that operate securely offline, free from the limitations and potential privacy concerns associated with cloud-based services and third-party APIs.
By architecturally integrating direct access to web resources, local file systems, raw data processing logic, and localized APIs, even low-powered consumer devices can now perform autonomous tasks that were previously exclusive to high-end cloud infrastructure. This opens up a plethora of opportunities for innovation across various sectors, from personalized digital assistants on mobile devices to intelligent automation in industrial IoT environments.
The demonstrated success of this local, privacy-first tool-calling agent using Gemma 4 and Ollama serves as a compelling blueprint for future AI development. The focus will undoubtedly shift towards building fully agentic systems that can proactively manage tasks, learn from interactions, and adapt to dynamic environments with minimal human intervention. The ongoing evolution of models like Gemma 4, combined with the growing maturity of local AI deployment platforms, signals a future where advanced AI is not only more accessible but also more aligned with user privacy and control.









{kind=link}