plea
-
Artificial Intelligence
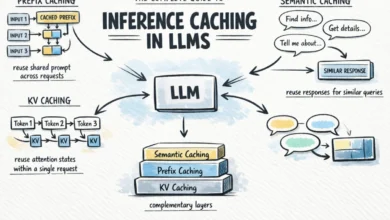
The Complete Guide to Inference Caching in LLMs
Calling a large language model (LLM) API at scale presents significant challenges, notably in terms of cost and latency. A…
Read More »

Calling a large language model (LLM) API at scale presents significant challenges, notably in terms of cost and latency. A…
Read More »