Google DeepMind has unveiled Gemma 4, its latest family of open large language models, marking a significant advancement in accessible artificial intelligence. These models are engineered for sophisticated reasoning and agentic workflows, promising an unprecedented level of intelligence relative to their parameter count. The launch builds upon the considerable momentum generated by the initial Gemma releases, which have seen over 400 million downloads and fostered a vibrant "Gemmaverse" of more than 100,000 community-developed variants. Gemma 4 is made available under a permissive Apache 2.0 license, aiming to empower developers with advanced AI capabilities while maintaining broad accessibility.
The introduction of Gemma 4 represents a strategic move by Google DeepMind to balance its proprietary AI offerings with powerful open-source solutions. This dual approach aims to cater to a diverse range of developer needs, from those requiring cutting-edge, managed services to innovators seeking complete control and flexibility over their AI deployments. The Gemma 4 models are built using the same foundational research and technology that powers Google’s Gemini models, positioning them as a potent complement within the industry’s AI toolkit.
A New Benchmark in Open Model Performance
Gemma 4 enters the open-source AI landscape with a clear objective: to deliver industry-leading capabilities without compromising on accessibility. The family comprises four distinct sizes, each meticulously optimized for different hardware and use cases. These include:
- Effective 2B (E2B): Designed for mobile and edge devices, prioritizing low-latency, multimodal capabilities, and seamless ecosystem integration.
- Effective 4B (E4B): Also geared towards on-device applications, offering enhanced performance for offline processing on smartphones, IoT devices, and embedded systems.
- 26B Mixture of Experts (MoE): This model focuses on delivering exceptional latency by activating only a subset of its parameters during inference, making it ideal for applications requiring rapid response times.
- 31B Dense: This model is engineered for maximum raw quality and offers a robust foundation for fine-tuning, pushing the boundaries of open-source model performance.
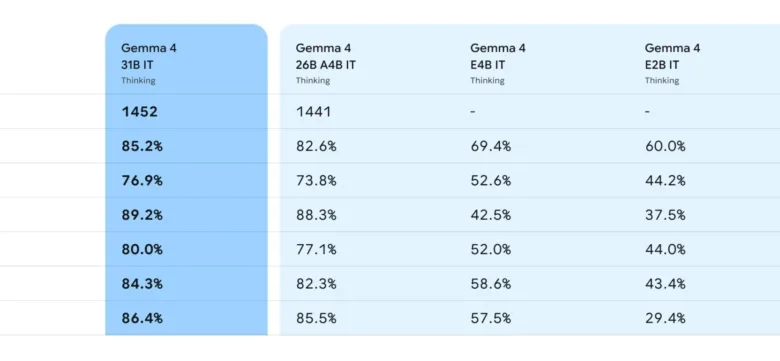
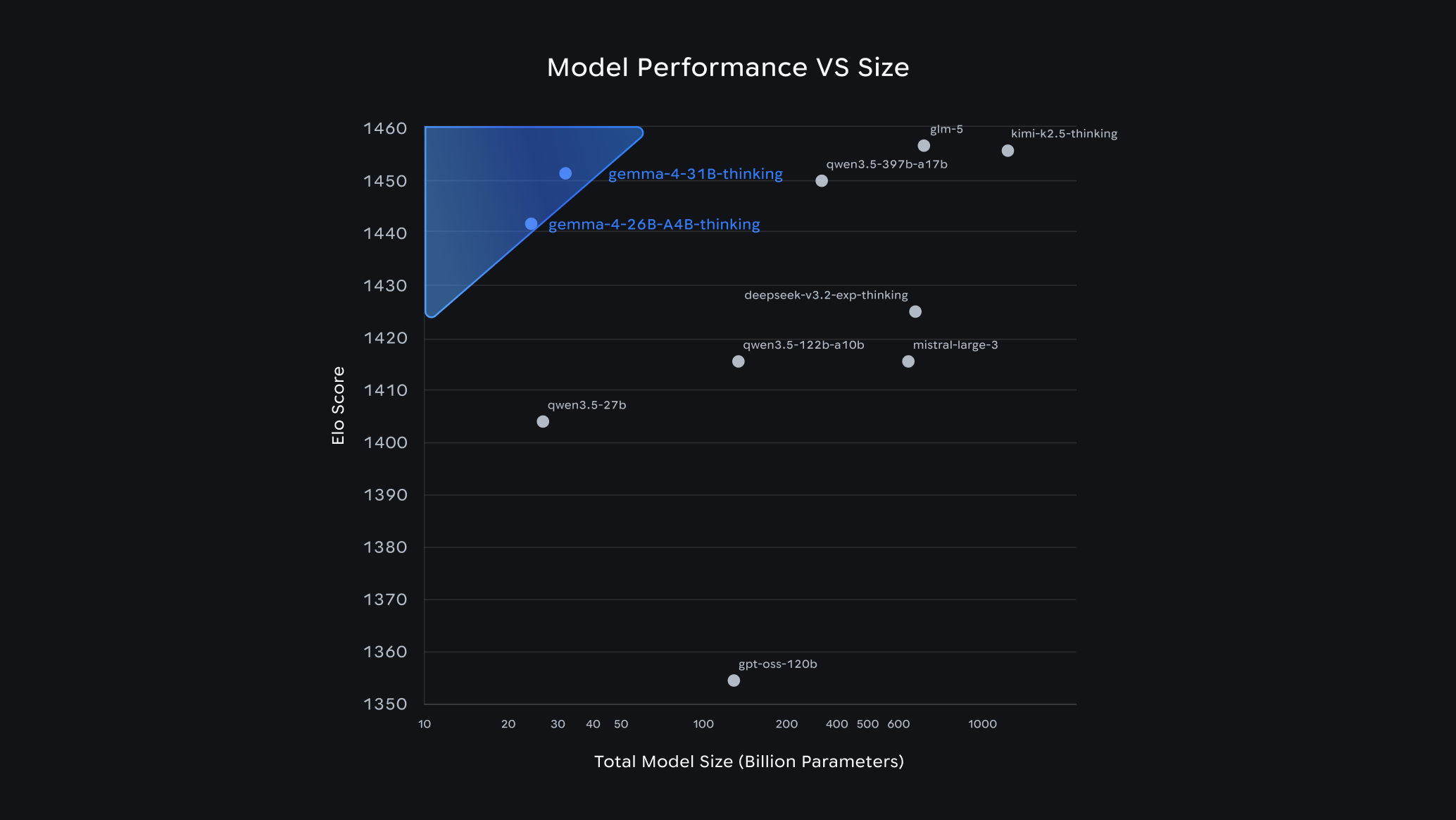
Early benchmarks highlight Gemma 4’s impressive standing. The 31B model currently ranks as the third-highest performing open model globally on the Arena AI text leaderboard, a widely recognized industry standard for evaluating LLM performance. The 26B model also secures a strong position, ranking sixth. Notably, Gemma 4 models demonstrate the ability to outperform models up to 20 times their size, a testament to their remarkable intelligence-per-parameter efficiency. This efficiency translates directly into tangible benefits for developers, enabling them to achieve state-of-the-art AI capabilities with significantly reduced hardware requirements and associated costs.
Background and Community Momentum
The release of Gemma 4 is not an isolated event but rather the culmination of sustained effort and community engagement. Since the initial launch of Gemma, the developer community has embraced the models with remarkable enthusiasm. The download figures, exceeding 400 million, underscore a strong demand for powerful yet accessible AI tools. The "Gemmaverse" has emerged as a testament to this, with over 100,000 community-driven variants demonstrating the adaptability and innovative potential of the Gemma architecture. This collaborative ecosystem has provided invaluable feedback and insights, directly influencing the development of Gemma 4.

Google DeepMind has emphasized its commitment to listening to the needs of innovators. The company states that it has "listened closely to what innovators need next to push the boundaries of AI." Gemma 4 is presented as the direct response to these needs, offering "breakthrough capabilities made widely accessible." This approach fosters a symbiotic relationship between Google and the developer community, where advancements in open models are driven by both top-tier research and the practical applications and creative solutions developed by users worldwide.
Industry-Leading Capabilities and Mobile-First AI
Gemma 4 represents a significant leap beyond traditional chat-based functionalities. The models are designed to handle complex logical reasoning and sophisticated agentic workflows, making them suitable for a new generation of AI-powered applications. This enhanced reasoning capability is particularly crucial for developing AI agents that can perform multi-step tasks, interact with their environment, and adapt to dynamic situations.
A key focus for Gemma 4 is its application in mobile and edge computing. The E2B and E4B models are specifically engineered for on-device deployment, a critical trend in the AI landscape. These models prioritize efficient computation and memory usage, enabling them to run offline on devices like Android phones, Raspberry Pi, and NVIDIA Jetson Orin Nano. This is achieved through close collaboration with key partners in the mobile hardware ecosystem, including the Google Pixel team, Qualcomm Technologies, and MediaTek.
The multimodal capabilities of these smaller Gemma 4 models are particularly noteworthy. They are designed to process and understand various forms of data, including text and potentially images, opening up new possibilities for on-device AI applications that are context-aware and interactive. Android developers can begin prototyping agentic flows using the AICore Developer Preview, which will offer forward compatibility with Gemini Nano 4, suggesting a clear roadmap for integrating advanced AI capabilities into the mobile experience.
Powerful, Accessible, and Open: The Apache 2.0 Advantage
The decision to release Gemma 4 under an Apache 2.0 license is a cornerstone of its accessibility strategy. This permissive license grants developers significant freedom to use, modify, and distribute the models, even for commercial purposes, without the encumbrances of more restrictive licenses. This approach is crucial for fostering innovation and ensuring that the benefits of advanced AI are widely shared.
The Apache 2.0 license provides developers with complete control over their data, infrastructure, and deployed models, a principle often referred to as "digital sovereignty." This is particularly important for enterprises and organizations that handle sensitive data or operate in regulated environments. The ability to build, deploy, and manage AI solutions securely, whether on-premises or in the cloud, without being locked into proprietary ecosystems, is a major draw for many.

Clément Delangue, co-founder and CEO of Hugging Face, a prominent platform for AI models and tools, commented on the significance of this release: "The release of Gemma 4 under an Apache 2.0 license is a huge milestone. We are incredibly excited to support the Gemma 4 family on Hugging Face on day one." This statement from a key player in the AI community underscores the impact and anticipation surrounding Gemma 4’s open availability.
A Foundation of Trust and Safety
Google DeepMind has underscored its commitment to security and responsible AI development with the Gemma 4 release. The models undergo the same rigorous infrastructure security protocols that are applied to Google’s proprietary models. This ensures that enterprises and sovereign organizations can leverage Gemma 4 with confidence, knowing they are utilizing a foundation that meets high standards for security and reliability.
The emphasis on trust and safety is paramount in the current AI landscape. By offering a transparent and secure open-source model, Google DeepMind aims to build confidence among users who may have concerns about data privacy, model bias, and ethical deployment. The same rigorous testing and evaluation that go into Google’s internal AI systems are applied to Gemma 4, providing a level of assurance that is critical for widespread adoption in sensitive applications.
Versatile Models for Diverse Hardware
The Gemma 4 model family is thoughtfully designed to cater to a wide spectrum of hardware capabilities, ensuring that advanced AI is not confined to high-end data centers.
-
26B and 31B Models: These larger models are optimized for state-of-the-art reasoning on accessible hardware. The unquantized bfloat16 weights of the 31B model, for instance, can fit efficiently on a single 80GB NVIDIA H100 GPU, a common component in research and enterprise settings. For local deployments on personal computers, quantized versions of these models can run natively on consumer-grade GPUs. This opens up possibilities for powerful AI-powered IDEs, sophisticated coding assistants, and advanced agentic workflows that can operate directly on a developer’s machine. The 26B MoE model’s focus on latency, activating only 3.8 billion parameters during inference, provides an exceptionally fast token-per-second rate, ideal for interactive applications. The 31B Dense model, conversely, prioritizes maximum raw quality, serving as a powerful base for fine-tuning and specialized tasks.
-
E2B and E4B Models: Engineered for maximum compute and memory efficiency, these models are designed to operate with minimal resource consumption. Their effective parameter footprints of 2 billion and 4 billion during inference are crucial for preserving RAM and battery life on mobile and IoT devices. The ability to run these multimodal models completely offline, with near-zero latency, on devices such as phones, Raspberry Pi, and NVIDIA Jetson Orin Nano, signifies a paradigm shift in on-device AI. This collaboration with mobile hardware leaders is key to unlocking the potential of pervasive AI, where intelligent assistants and applications can function seamlessly without constant internet connectivity.
An Ecosystem of Choices and Future Implications
The release of Gemma 4, coupled with its permissive licensing and focus on diverse hardware, is poised to catalyze further innovation within the AI community. The broad accessibility of these advanced models democratizes AI development, enabling smaller teams, individual researchers, and organizations with limited resources to experiment with and build upon cutting-edge technology.
The implications are far-reaching. We can anticipate a surge in novel AI applications across various sectors, from enhanced productivity tools and personalized educational platforms to more sophisticated scientific research and creative endeavors. The emphasis on agentic workflows suggests a future where AI systems can act more autonomously, assisting humans in complex decision-making and task execution.
The success of fine-tuning initiatives, such as INSAIT’s creation of a Bulgarian-first language model (BgGPT) and Yale University’s work on Cell2Sentence-Scale for cancer therapy discovery, demonstrates the power of adapting Gemma models to specific domains. Gemma 4 is expected to accelerate these kinds of specialized AI developments, leading to more tailored and effective solutions for real-world problems.
Furthermore, the collaboration with Android developers on the AICore Developer Preview signals a commitment to integrating these AI capabilities deeply into the mobile operating system. This suggests a future where AI is not just an add-on but an intrinsic part of the user experience on billions of devices worldwide.
In essence, Gemma 4 represents Google DeepMind’s strategic vision for the future of AI: a future that is intelligent, accessible, and collaborative. By providing powerful open-source models under a permissive license, the company is empowering a global community to build the next generation of AI, driving innovation and democratizing access to advanced artificial intelligence. The "byte for byte" claim of capability suggests a meticulous engineering approach, focusing on maximizing the value and performance derived from each parameter, ultimately setting a new standard for what open models can achieve.