Handling Race Conditions in Multi-Agent Orchestration Systems: A Comprehensive Guide
In the rapidly evolving landscape of artificial intelligence, multi-agent orchestration systems are emerging as powerful tools for tackling complex tasks. These systems, which empower multiple AI agents to collaborate and execute tasks concurrently, promise unprecedented efficiency and problem-solving capabilities. However, their very design, which relies on parallel execution, introduces a significant challenge: race conditions. These insidious bugs can lead to unpredictable behavior, data corruption, and system instability, particularly in high-stakes production environments. Understanding, identifying, and mitigating race conditions is no longer a defensive measure but a fundamental requirement for building robust and reliable multi-agent systems.
The Silent Threat: Understanding Race Conditions in Multi-Agent Systems
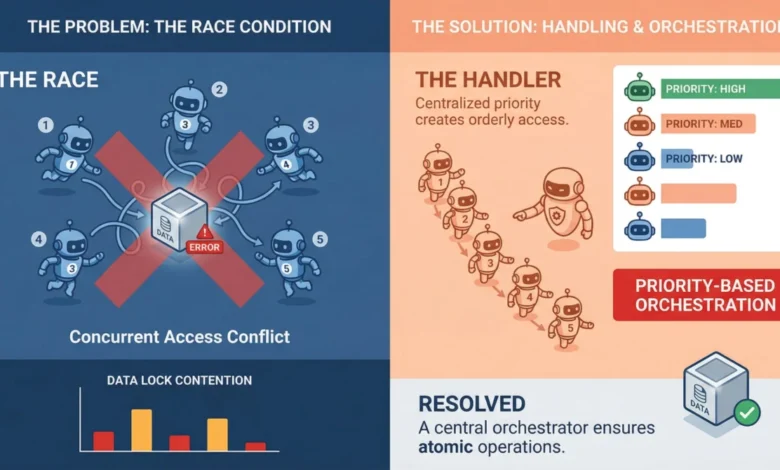
At its core, a race condition occurs when two or more agents attempt to access, modify, or write to shared data concurrently. The outcome of these operations becomes dependent on the precise timing of each agent’s execution, leading to an unpredictable and often erroneous final state. While such conditions can manifest as outright crashes, they are more frequently characterized by subtle data corruption that evades immediate detection. Imagine Agent A reading a critical piece of information, only for Agent B to modify it moments later. If Agent A then proceeds to write its stale data back, the system might appear operational, but its underlying data integrity has been compromised.
This challenge is amplified within machine learning pipelines, where agents frequently interact with mutable shared objects. These can range from shared memory stores and vector databases to tool output caches and task queues. Each of these shared resources becomes a potential point of contention when multiple agents simultaneously attempt to access and manipulate them. The consequence is not a loud failure, but a quiet erosion of data accuracy, leading to flawed analyses, incorrect predictions, or failed downstream processes.
Why Multi-Agent Pipelines are Particularly Vulnerable
The nature of multi-agent systems, especially those built around Large Language Models (LLMs), presents unique vulnerabilities not always present in traditional concurrent programming. Decades of research have yielded robust solutions for managing concurrency in single-threaded or thread-based applications, including mutexes, semaphores, and atomic operations. However, modern multi-agent frameworks often leverage asynchronous programming models, message brokers, and sophisticated orchestration layers. These components, while enabling powerful parallel execution, may not always offer the fine-grained control over execution order that is crucial for preventing race conditions.
Compounding this complexity is the inherent non-determinism of LLM agents. The time it takes for an LLM agent to complete a task can vary significantly. One agent might respond in milliseconds, while another might take several seconds to process a complex query. When an orchestrator fails to gracefully handle these temporal discrepancies, agents can begin to interfere with each other’s operations, leading to the aforementioned silent data corruption.
Furthermore, the communication patterns between agents play a critical role. Systems that rely on agents directly modifying a central object or a shared database row are almost guaranteed to encounter write conflicts at scale. This is less a technical bug and more a fundamental architectural design flaw. Addressing such issues often requires a re-evaluation of the system’s overall architecture before any code-level modifications can be effective.
Mitigation Strategies: Locking, Queuing, and Event-Driven Architectures
Several well-established strategies can be employed to mitigate race conditions in multi-agent systems, each with its own trade-offs:
-
Locking Mechanisms: The most direct approach to managing shared resource contention is through locking.
- Optimistic Locking: This strategy is effective when conflicts are anticipated to be infrequent. Each agent reads a data record along with a version identifier. Before writing, the agent checks if the version has changed since it was read. If it has, the write operation fails, prompting a retry with the latest data.
- Pessimistic Locking: This more aggressive approach involves acquiring an exclusive lock on a resource before it is read or modified. This guarantees that only one agent can access the resource at a time, but it can significantly reduce parallelism if many agents are vying for the same lock, potentially creating bottlenecks and decreasing overall throughput.
-
Queuing Systems: Queuing offers a robust solution, particularly for task assignment and management. Instead of multiple agents directly accessing and modifying a shared task list, tasks are placed into a queue, and agents consume them sequentially. Technologies like Redis Streams, RabbitMQ, or even database-level advisory locks can serve as effective serialization points, removing the race condition from the task consumption process.
-
Event-Driven Architectures: Moving beyond direct state manipulation, event-driven architectures promote looser coupling and reduced overlap windows. In this model, agents react to events emitted by other agents. For instance, Agent A completes its task and publishes an "TaskCompleted" event. Agent B, listening for this event, then picks up the subsequent task. This reactive approach naturally minimizes the likelihood of concurrent modifications to the same data.
The Indispensable Role of Idempotency
Even with robust locking and queuing mechanisms in place, system failures and retries can still lead to duplicated operations. This is where idempotency becomes paramount. An idempotent operation is one that can be executed multiple times without altering the outcome beyond the initial execution.
For agents, this typically means incorporating unique operation identifiers with every write or modification request. If the system receives a request with an ID it has already processed, it can safely ignore the duplicate. This small design choice significantly enhances system reliability, especially in the face of network hiccups, timeouts, or agent restarts. Building idempotency into agents from the outset, rather than attempting to retrofit it later, is a crucial step in creating resilient multi-agent systems. Agents that interact with databases, update records, or trigger external workflows should all possess some form of deduplication logic.
Proactive Testing: Uncovering Race Conditions Before They Surface
The elusive nature of race conditions, stemming from their dependence on specific timing and execution sequences, makes them notoriously difficult to reproduce in standard testing environments. They often manifest only under heavy load or in rare, complex interaction patterns.
To combat this, a multi-pronged testing approach is recommended:
-
Stress Testing with Intentional Concurrency: This involves simulating the kind of overlapping execution that triggers race conditions. Tools like Locust, or the concurrent task capabilities of libraries like
pytest-asyncio, can be used to spin up multiple agents simultaneously against shared resources. Observing system behavior under such stress can reveal contention bugs in staging environments before they impact production. -
Property-Based Testing: While less commonly applied to concurrency issues, property-based testing can be highly effective. This approach involves defining invariants – conditions that should always hold true, regardless of execution order. Randomized tests are then run to attempt to violate these invariants. While it may not uncover every race condition, it is adept at surfacing subtle consistency issues that deterministic tests often miss.
A Concrete Illustration: The Shared Counter Dilemma
To solidify understanding, consider a simple yet illustrative scenario: a shared counter that multiple agents increment concurrently. This scenario, while basic, mirrors real-world situations where agents might track document processing counts or task completion metrics.
In pseudocode, the problematic operation looks like this:
# Shared state
counter = 0
# Agent task
def increment_counter():
global counter
value = counter # Step 1: read
value = value + 1 # Step 2: modify
counter = value # Step 3: writeNow, imagine two agents executing this increment_counter function simultaneously. Agent 1 reads counter (which is 0). Before Agent 1 can write its incremented value back, Agent 2 also reads counter (still 0). Both agents then proceed to increment their local value to 1 and write it back to counter. The expected final value should be 2, but due to the race condition, the actual final value will be 1. This occurs without any error messages or warnings, highlighting the silent nature of the problem.
Several mitigation strategies can be applied to this scenario:
-
Option 1: Locking the Critical Section
By introducing a lock, we ensure that only one agent can execute the read-modify-write sequence at a time.
lock.acquire() value = counter value = value + 1 counter = value lock.release()This guarantees correctness but at the cost of reduced parallelism. If many agents frequently contend for the same lock, system throughput can suffer significantly.
-
Option 2: Atomic Operations
If the underlying infrastructure supports it, atomic operations offer a cleaner and more efficient solution. Instead of breaking the operation into discrete steps, it is delegated to the system as a single, indivisible unit.
counter = atomic_increment(counter)Databases, key-value stores, and certain in-memory systems provide atomic increment operations, effectively eliminating the race condition by making the update indivisible.
-
Option 3: Idempotent Writes with Versioning (Optimistic Locking)
This approach involves detecting and rejecting conflicting updates through versioning.
# Read with version value, version = read_counter() # Attempt write success = write_counter(value + 1, expected_version=version) if not success: retry()This is optimistic locking in practice. If another agent modifies the counter first, the write operation fails because the
expected_versiondoes not match the current version. The agent then retries with the latest data.
In complex multi-agent systems, the "counter" might represent a document, a state object, or an entry in a memory store. The fundamental principle remains the same: any operation that splits a read from a write creates a window for interference. Effectively closing this window through locks, atomic operations, or robust conflict detection is the cornerstone of handling race conditions.
Conclusion: Building for Predictability in a Chaotic Environment
Race conditions in multi-agent orchestration systems are not insurmountable obstacles but rather inherent characteristics that demand deliberate design. The systems that effectively manage these challenges are not those that have been fortunate enough to avoid timing-related issues, but rather those that anticipate concurrency-induced problems and proactively implement solutions.
Idempotent operations, event-driven communication patterns, judicious use of locking mechanisms, and well-managed queuing systems are not indicative of over-engineering. They represent the foundational principles for building reliable pipelines where agents operate in parallel without undermining each other’s work. By establishing these fundamentals, developers can create multi-agent systems that are not only powerful but also predictable and robust in the face of real-world execution complexities.




