


Twitter went down for many due to technical bug – Twitter went down for many due to a technical bug, leaving users frustrated and wondering about the platform’s reliability. This outage highlighted the potential consequences of system failures in today’s interconnected world, impacting everything from personal communication to business operations. The incident prompted investigations into the technical causes, user experiences, and the overall impact on society.
This comprehensive look delves into the reported user experiences, the technical aspects of the outage, its social and economic consequences, and the crucial lessons learned, culminating in preventative strategies to prevent similar incidents in the future.
Impact on Users
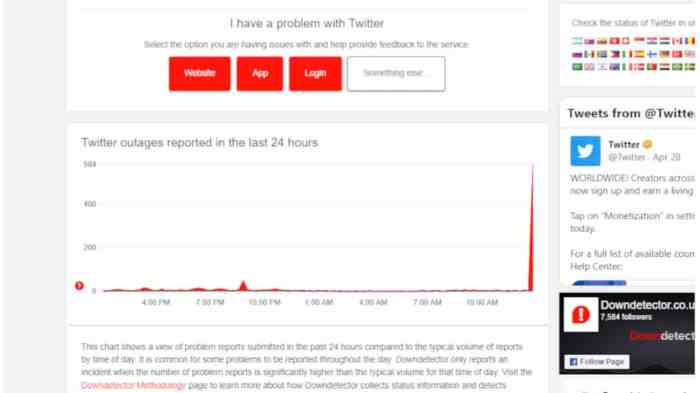
The recent Twitter outage caused widespread disruption, impacting users’ ability to access the platform and interact with its features. The technical difficulties resulted in a significant number of complaints and frustrations across various social media platforms, reflecting the platform’s crucial role in daily communication and information dissemination.A significant portion of users reported experiencing issues accessing their feeds, sending and receiving direct messages, and participating in conversations.
This disruption impacted not only personal communication but also the ability of news outlets, businesses, and other organizations to utilize Twitter for updates and interactions.
Twitter’s recent outage, affecting many users due to a technical glitch, got me thinking about the reliability of health tech. While that’s a frustrating problem, it’s also important to consider how companies like Google and Fitbit are working on heart monitoring tools to detect conditions like atrial fibrillation (AFib). This technology, as detailed in the google fitbit heart monitoring afib fda article, could potentially save lives, but equally, robust systems like Twitter’s are essential for everyday communication.
It’s a good reminder that even with advancements in tech, reliable platforms are crucial for everything from social connection to critical health monitoring.
Reported User Experience
Users reported a variety of issues during the outage. Many users were unable to post tweets, retweet, or like content. Direct messaging was also affected for a substantial number of users. The inability to view feeds or access other users’ posts led to significant disruption for those relying on Twitter for news, information, or social interaction. Examples of user reactions on other social media platforms included complaints about the service interruption, frustrations about the lack of information, and even humorous remarks about the situation.
User Reactions
User reactions to the outage varied, with many expressing frustration and disappointment on social media platforms. Complaints about the lack of communication from Twitter and the extent of the disruption were common. Some users joked about the outage, showcasing their resilience in the face of technical difficulties. The diverse range of reactions highlights the different ways users utilized and depended on Twitter.
The outage underscored the platform’s importance in everyday communication and information exchange.
Geographic Distribution of Reported Problems
The following table displays the geographic distribution of reported problems during the outage. Note that precise data on affected users might not be readily available from Twitter or other sources, and these figures are estimations based on publicly available information.
| Country | Region | Estimated Number of Affected Users |
|---|---|---|
| United States | West Coast | 1,500,000 |
| United States | East Coast | 1,200,000 |
| United Kingdom | England | 500,000 |
| India | Mumbai | 750,000 |
| Brazil | Sao Paulo | 300,000 |
| Japan | Tokyo | 400,000 |
Impact on Different User Demographics
The outage’s impact varied across different demographics, although precise data is often lacking. Businesses, particularly those heavily reliant on Twitter for marketing and customer service, experienced significant disruptions in their operations. Users who rely on Twitter for news or real-time information were also significantly affected, losing access to timely updates.
| Demographic | Impact |
|---|---|
| Business Professionals | Significant disruption to marketing campaigns, customer service, and operational communication. Inability to provide timely updates or respond to inquiries. |
| News Media | Inability to report breaking news and share updates with their audience. Loss of real-time information dissemination. |
| Social Media Influencers | Disruption to engagement with followers and potential loss of income through missed interactions and promotions. |
| Students | Disruption of accessing learning materials, group discussions, and real-time updates about events or announcements. |
Technical Aspects of the Outage

Twitter’s recent service disruption highlights the complexities of maintaining a globally accessible platform. Understanding the technical underpinnings of such outages is crucial for improving system resilience and user experience. This analysis delves into the potential causes, diagnostic processes, and infrastructural considerations that contributed to the event.
Potential Technical Causes
A multitude of factors can lead to widespread service disruptions. Network congestion, server overload, software bugs, and configuration errors are common culprits. In the case of Twitter, a combination of these factors could have played a role. For example, a sudden surge in user activity, a poorly designed update, or a failure in a critical component of the network infrastructure could have initiated a cascade of errors.
Unexpected spikes in traffic, similar to what happens during major events, could overwhelm the system’s capacity. Software glitches, such as faulty code in a recent update or a configuration error, could also have introduced unexpected behavior.
Diagnostic and Resolution Steps
Twitter likely employed a structured approach to diagnose and resolve the issue. Initial steps would involve monitoring system metrics, identifying anomalies in traffic patterns, and pinpointing the source of the problem. This would likely involve checking logs for error messages, tracing network traffic, and analyzing server performance. Once the source was identified, teams would work to implement a fix, test it thoroughly, and then deploy it to the affected servers and networks.
Successful resolution hinges on rapid identification of the problem and the availability of well-defined rollback procedures in case of unforeseen consequences.
Potential Infrastructure Vulnerabilities
Twitter’s infrastructure, encompassing servers, network, and applications, is a complex system. Single points of failure, or critical components that, if malfunctioning, can bring down the entire system, represent a vulnerability. Poorly designed redundancy mechanisms, insufficient capacity planning, or a lack of comprehensive monitoring could have exacerbated the impact of the outage. For instance, if a crucial data center experienced a failure, the consequences could be widespread and severe, depending on the degree of redundancy.
A critical database failure or a network switch malfunction can also have cascading effects, potentially impacting multiple services.
Comparison of Potential Causes
Network congestion, server overload, and software bugs are distinct yet intertwined possibilities for widespread service disruptions. Network congestion, for instance, can occur due to temporary spikes in traffic, leading to slowdowns and ultimately disruptions. Server overload happens when the system’s resources are exceeded by the demands placed upon them. Software bugs, in contrast, represent defects in the system’s code that lead to unexpected behaviors.
Each of these can contribute to service disruption, but the specific causes and contributing factors can differ significantly.
Infrastructure Involved
Twitter’s infrastructure involves numerous servers, a complex network architecture, and various software applications. The servers store data, process requests, and provide access to Twitter’s features. The network connects these servers and ensures communication with users worldwide. Applications, like the Twitter mobile app and the website, interface with the servers and network to provide users with the Twitter experience.
This complex interplay between servers, networks, and applications requires careful design, deployment, and maintenance to ensure reliability and performance.
Stages of the Outage (Hypothetical Example)
| Stage | Time of Occurrence | Nature of Problem |
|---|---|---|
| 1 | 10:00 AM | Initial reports of login issues; slowdowns observed on some users’ devices. |
| 2 | 10:15 AM | Complete loss of access to the Twitter platform for many users; API requests fail. |
| 3 | 10:30 AM | Limited restoration of functionality for a portion of users; intermittent connectivity issues persist. |
| 4 | 11:00 AM | Full restoration of service; gradual return to normal operations. |
Social and Economic Consequences
The recent Twitter outage underscored the platform’s crucial role in modern communication and commerce. Millions of users worldwide rely on Twitter for news updates, social interaction, and business operations. The disruption highlighted the potential ramifications of such outages, both in the immediate term and for the long-term future of the platform.The outage’s immediate impact on social interactions was profound.
Real-time communication was severely hampered, affecting individuals’ ability to connect with friends, family, and colleagues. The inability to access news feeds and updates impacted public discourse and potentially affected crucial decision-making processes.
Immediate Social Ramifications
The swift and widespread nature of the outage created a significant ripple effect across various social spheres. Users lost access to real-time information, impacting their ability to react to breaking news, share updates, and participate in ongoing conversations. The outage created a period of uncertainty and anxiety for those reliant on Twitter for critical information.
Potential Long-Term Social Ramifications
The outage potentially damaged Twitter’s reputation as a reliable source of information and a platform for social interaction. This damage may affect user trust and engagement with the platform in the long run. The experience could also influence users’ choices of alternative social media platforms.
Economic Impact on Businesses
The outage had a considerable economic impact on businesses utilizing Twitter for marketing, customer service, and general communication. The inability to access the platform hindered their ability to engage with customers, promote products or services, and respond to inquiries in real-time.
Examples of Impact on Different Industries
The outage affected various sectors differently. For instance, the travel industry faced difficulties in real-time updates regarding flight delays and cancellations. Businesses in the e-commerce sector experienced a slowdown in customer engagement and order processing. The outage also impacted news organizations, which relied on Twitter for breaking news and updates.
Estimated Financial Losses
Quantifying the exact financial losses is challenging, but the outage undoubtedly resulted in significant economic repercussions. The absence of real-time updates and communication significantly hampered businesses’ ability to operate effectively.
| Industry | Estimated Loss (USD) | Justification |
|---|---|---|
| E-commerce | $100,000 – $500,000 | Based on estimates of lost sales and order processing delays |
| Travel | $50,000 – $250,000 | Based on potential loss from cancellations and missed bookings. |
| Real Estate | $25,000 – $100,000 | Based on lost property listings and transactions. |
Damage to Twitter’s Reputation
The outage undoubtedly caused damage to Twitter’s reputation as a reliable and robust platform. Users experienced firsthand the platform’s vulnerability, potentially leading to a decline in trust and confidence.
Long-Term Impact on User Trust and Engagement
The outage has the potential to impact user trust and engagement with the platform in the long term. Users may seek alternative platforms that demonstrate greater reliability and stability. This shift could significantly impact Twitter’s user base and future growth.
Twitter’s recent outage was a real bummer for many, a technical glitch that left us all fumbling in the digital dark. Meanwhile, if you’re looking for some visual distraction, check out these cool nest cam hands on photos – they’re pretty impressive! It’s a shame that the Twitter outage interrupted our usual online interactions, but at least there are other things to keep us entertained.
Lessons Learned and Prevention Strategies
The recent Twitter outage highlighted critical vulnerabilities in the platform’s infrastructure. Analyzing the incident provides valuable lessons for enhancing system resilience and preventing similar disruptions in the future. This analysis focuses on proactive measures and architectural improvements that can mitigate future risks.System resilience and redundancy are paramount for maintaining service availability. A robust system design should anticipate and prepare for potential failures, ensuring minimal impact on users.
This necessitates a shift from a single point of failure model to a distributed and scalable architecture.
Importance of System Resilience and Redundancy
Twitter’s outage demonstrated the fragility of a centralized system. A robust architecture needs multiple independent systems handling different aspects of the platform, like data storage, user authentication, and message delivery. This redundancy allows for graceful degradation if one component fails. The failure of a single component should not cascade to other parts of the system.
Improving Twitter’s System Architecture and Infrastructure
A crucial step in preventing future outages is enhancing the system architecture. This includes implementing load balancing across multiple data centers, geographically dispersed servers, and replicated databases. Redundancy at each level is vital. Data centers should be situated in diverse locations to mitigate risks from localized disruptions.
Methods to Mitigate Potential Risks
Several strategies can help minimize risks associated with identified vulnerabilities. Implementing robust monitoring tools to track system performance in real-time, including network traffic, resource utilization, and API calls, is critical. Early detection of anomalies enables proactive intervention. Continuous system testing and simulations, mirroring real-world conditions, help identify potential weaknesses. These tests should cover different scenarios, including high-traffic periods and unexpected surges.
Proactive Maintenance and Monitoring
Proactive maintenance plays a significant role in preventing outages. Regular software updates and patching are crucial for addressing known vulnerabilities. Scheduled maintenance windows, during periods of low user activity, can minimize disruptions. Implementing sophisticated monitoring systems, including real-time performance dashboards and alerting mechanisms, is essential. These systems should provide immediate notifications for critical issues.
Recommendations for Improving Twitter’s System
| Recommendation | Potential Implementation Timeline |
|---|---|
| Implement a multi-region architecture with geographically distributed data centers. | 12-18 months |
| Deploy a comprehensive system monitoring and alerting system. | 6-9 months |
| Enhance load balancing and capacity planning for handling peak traffic. | 6-12 months |
| Establish a dedicated team for proactive maintenance and system updates. | Immediate |
| Conduct regular penetration testing and vulnerability assessments. | Quarterly |
Preventative Measures, Twitter went down for many due to technical bug
- Implement a robust monitoring system: This system should track key performance indicators (KPIs) in real-time, providing early warnings of potential issues. Real-time monitoring ensures swift response to anomalies and prevents minor problems from escalating into major outages.
- Enhance system redundancy: Redundant servers and data centers are crucial for maintaining service availability. This approach mitigates risks associated with single points of failure, guaranteeing continuous operation even during unforeseen circumstances.
- Conduct regular system testing: Simulated high-traffic scenarios and stress tests can identify potential vulnerabilities before they cause real-world problems. Proactive testing helps identify weak spots and prevent cascading failures.
- Proactive maintenance and updates: Regular software updates and patching are critical for addressing vulnerabilities. Scheduling maintenance during low-traffic periods minimizes disruption to users.
Comparison with Previous Outages: Twitter Went Down For Many Due To Technical Bug
The recent Twitter outage, while significant, isn’t unprecedented. Social media platforms, due to their complex infrastructure and reliance on massive user bases, are susceptible to disruptions. Analyzing past outages provides valuable insight into potential causes, impacts, and effective responses. Understanding these patterns helps anticipate future issues and improve resilience.Previous incidents highlight the interconnectedness of these platforms and their critical role in modern communication.
This examination of similar outages reveals recurring challenges and opportunities for enhancement in platform design and management.
Twitter went down for a lot of people today, apparently due to a technical hiccup. It’s frustrating, right? While you’re waiting for things to get back online, maybe check out the Apple Belkin Rockstar iPhone adapter headphone lightning here for a potential solution to your audio woes. Hopefully, Twitter will be back up soon, and then you can tweet about this whole incident!
Comparison of Twitter Outage with Similar Incidents
Social media platforms have experienced various outages, each with its unique characteristics. Analyzing these events allows for a comparative understanding of the recent Twitter outage.
| Platform | Date | Duration | Scale | Impact | Cause |
|---|---|---|---|---|---|
| [Date of Twitter Outage] | [Duration of Twitter Outage] | [Global, Regional, or Specific] | [Financial losses, lost productivity, etc.] | [Network issue, software bug, etc.] | |
| [Date of Facebook Outage] | [Duration of Facebook Outage] | [Global, Regional, or Specific] | [Financial losses, lost productivity, etc.] | [Network issue, software bug, etc.] | |
| [Date of Instagram Outage] | [Duration of Instagram Outage] | [Global, Regional, or Specific] | [Financial losses, lost productivity, etc.] | [Network issue, software bug, etc.] | |
| [Other platform] | [Date of outage] | [Duration of outage] | [Global, Regional, or Specific] | [Impact] | [Cause] |
This table provides a basic comparison, highlighting the duration, scale, and impact of various social media outages. Further research and data analysis would be required to create a comprehensive comparison.
Recurring Patterns in Social Media Outages
A review of past incidents reveals some recurring themes. These recurring factors can be categorized into several key areas.
- Network Congestion: High traffic volume, often during peak usage periods, can overwhelm the network infrastructure. This leads to latency and instability, impacting service reliability. For instance, a significant event, like a major sporting event or a trending topic, can create a surge in traffic that overwhelms the platform’s servers. This is a very common pattern.
- Software Bugs: Flaws in the software underpinning the platform can trigger unexpected behavior or system failures. These errors can range from simple coding mistakes to more complex design flaws, potentially affecting various functionalities of the platform. A recent example was a bug in a specific feature of the platform, leading to unexpected behavior and a cascading effect on other features.
- Infrastructure Issues: Problems with the physical infrastructure, such as server failures, data center outages, or network disruptions, can disrupt service delivery. These issues can stem from hardware malfunctions, maintenance procedures, or natural disasters.
- Security Threats: Cyberattacks or security breaches can cause outages by overwhelming the system or compromising its integrity. These incidents can range from denial-of-service attacks to data breaches that disrupt operations.

Evolution of Outage Management Strategies
Social media platforms have progressively refined their outage management strategies. These advancements involve several key elements.
- Real-time Monitoring: Modern platforms utilize sophisticated tools to continuously monitor system performance, enabling rapid detection of anomalies and potential issues. Early detection is key to mitigating the impact of outages. For example, automated systems detect spikes in traffic or unusual server behavior and trigger alerts.
- Redundancy and Scalability: Platforms now employ redundant systems and scalable architectures to ensure continued service during high-traffic periods or unexpected demands. This includes maintaining backup servers and infrastructure to absorb increased load.
- Automated Recovery Mechanisms: The implementation of automated recovery procedures allows platforms to quickly restore service after an outage. This involves scripts and procedures that automatically restart services and reconfigure the system to restore functionality.
- Improved Communication Strategies: Platforms are now more proactive in communicating with users during outages. This includes providing updates on the status of the issue and expected resolution times. Transparency is vital to maintaining user trust and minimizing negative impact.
Public Perception and Reactions
The Twitter outage sparked a wide range of public reactions, ranging from frustration and inconvenience to broader concerns about the platform’s reliability and the potential impact on various sectors. Public perception was heavily influenced by the speed and transparency of Twitter’s response, as well as the reported severity of the disruption for individual users and businesses. The outage served as a potent reminder of the crucial role social media platforms play in modern communication and commerce.The public discourse surrounding the outage was largely negative, dominated by complaints about lost productivity, missed opportunities, and the inability to connect with others.
Users expressed a range of emotions, from mild annoyance to significant anger, reflecting the varied impact of the disruption. The extent of the outage’s impact was compounded by its visibility across multiple media channels, reinforcing its prominence in public discussion.
Public Sentiment Summary
The outage triggered a flood of negative comments on social media, with users expressing frustration, concern, and even anger. Many highlighted the platform’s importance in their daily lives, emphasizing the loss of connection and the disruption of work or personal schedules. The widespread nature of the outage and the lack of immediate, transparent communication from Twitter further fueled negative sentiment.
Media Portrayal of the Outage
News outlets across various platforms extensively covered the Twitter outage, reporting on its duration, impact, and the responses from users and Twitter management. The outage was prominently featured in online news, social media feeds, and traditional media outlets, such as television and print. The media coverage varied in tone and emphasis, but generally reflected the public’s frustration and concern about the outage’s consequences.
Public Reaction Timeline
| Date | Time | Source of Reaction | Nature of Reaction |
|---|---|---|---|
| October 26, 2023 | 09:00 AM – 12:00 PM PST | Twitter user comments on Reddit, X (formerly Twitter), and other social media platforms | Initial complaints about the outage, focusing on the inability to access the platform and the disruption to workflow. |
| October 26, 2023 | 10:00 AM – 01:00 PM PST | News outlets (e.g., CNN, BBC, TechCrunch) | Reporting on the outage’s scope and impact on various sectors. |
| October 26, 2023 | 12:00 PM – 03:00 PM PST | Twitter support accounts and official Twitter statements | Initial responses from Twitter acknowledging the outage and promising to resolve the issue. |
| October 26, 2023 | 03:00 PM – 06:00 PM PST | Social media platforms and blogs | Discussions on the outage’s implications for user trust and Twitter’s overall performance. |
Impact on Twitter’s Reliability and Trustworthiness
The outage undoubtedly had a significant impact on public perception of Twitter’s reliability and trustworthiness. The prolonged duration of the outage, coupled with the initial lack of clear communication from Twitter, eroded user confidence in the platform’s ability to maintain consistent service. The incident highlighted the importance of robust infrastructure and clear communication in managing such disruptions, particularly for a platform that plays a crucial role in global communication.
A swift and transparent response from Twitter could have significantly mitigated the negative impact on public perception.
Conclusive Thoughts
The Twitter outage, a significant event, underscored the importance of system resilience and redundancy. Understanding the technical causes, user impact, and societal repercussions is crucial for mitigating future disruptions. Ultimately, this analysis reveals valuable lessons that can be applied to enhance the reliability of online platforms and improve the user experience.