

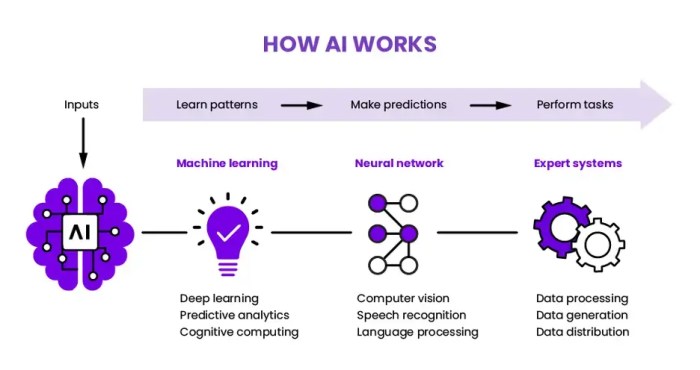
Google ai data privacy tensorflow differential module code – Google AI data privacy, TensorFlow differential module code unlocks a fascinating world of responsible AI development. This exploration delves into Google’s data privacy policies, examining how the TensorFlow Differential Module enables privacy-preserving AI model training. We’ll explore different techniques, from anonymization to federated learning, and see how Google’s approach compares to others in the industry.
The TensorFlow Differential Module empowers developers to build AI models while upholding stringent data privacy standards. This module allows for controlled access to sensitive data, reducing the risks associated with training AI on potentially private information. We’ll examine the module’s core functionality and its role in enhancing privacy during model training, touching upon the mathematical underpinnings of its operations and illustrating its practical applications.
Introduction to Google AI Data Privacy
Google’s approach to AI data privacy is multifaceted, encompassing policies, practices, and ethical considerations. Their commitment to responsible AI development involves stringent data handling procedures, emphasizing user control and transparency. This commitment extends beyond legal compliance to proactive measures that prioritize user trust and data security.Google’s data privacy policies are designed to balance innovation in AI with user rights and safety.
This intricate balance is critical in navigating the complexities of data usage for advanced AI models while ensuring that personal information is protected and used responsibly.
Google’s AI Data Privacy Policies and Practices
Google adheres to a comprehensive set of principles in handling data used for AI projects. These principles are crucial for building trust and ensuring responsible AI development. Google’s commitment to user privacy is a cornerstone of their AI initiatives.
- Data Minimization: Google strives to collect only the necessary data for specific AI tasks, avoiding excessive data collection. This principle is essential for preventing the accumulation of unnecessary personal information. For example, Google might collect only the user’s email address for a specific AI-powered email filtering service, avoiding the collection of other personal details.
- Data Security: Google employs robust security measures to protect user data from unauthorized access, use, or disclosure. These measures include encryption, access controls, and regular security audits to maintain the integrity and confidentiality of personal data. For instance, Google uses encryption for data transmission and storage to safeguard user information from potential threats.
- User Control and Transparency: Google grants users control over their data, allowing them to access, correct, and delete their personal information. Transparency is prioritized through clear data usage policies and mechanisms for user feedback and reporting. Users can review and manage their data settings within Google services to control how their information is used for AI projects.
Types of Data Used in Google AI Projects
Google AI projects utilize diverse data types, each with unique implications for privacy. Understanding these data types is essential to appreciate the complexities of AI development and data handling.
- User-Generated Data: This includes data directly submitted by users, such as text, images, videos, and audio. For example, user-generated data for image recognition projects could include pictures uploaded to Google Photos or images shared on Google+. This data is often crucial for training AI models.
- Metadata: Metadata associated with user-generated data provides context and additional information. This metadata can include timestamps, location data, and device information. For example, in a Google Maps application, metadata associated with user location data might include the time and date of the location visit, the user’s device, and the application used.
- Aggregated Data: This data type involves combining individual user data points into larger, anonymized sets. Aggregated data provides insights into trends and patterns without identifying individual users. For example, Google might analyze aggregated data on search queries to understand user interests without revealing specific search terms of individual users.
Risks and Ethical Considerations in AI Data Privacy
Data privacy in AI development presents several risks and ethical considerations. These challenges necessitate careful consideration and proactive mitigation strategies.
- Bias and Discrimination: AI models trained on biased data can perpetuate and amplify existing societal biases. This can lead to discriminatory outcomes, particularly for vulnerable groups. For instance, if an AI model for loan applications is trained on data that disproportionately favors certain demographics, it may unfairly deny loans to other groups.
- Data Breaches: Data breaches can expose sensitive user information to unauthorized individuals or entities. This can lead to identity theft, financial loss, and reputational damage. For example, a data breach affecting a user’s Google account could expose their personal information, including emails, photos, and financial details.
- Lack of Transparency: The complex nature of some AI models can make it difficult to understand how they arrive at their decisions. This lack of transparency can erode trust and create difficulties in accountability. For instance, a user may not understand the factors influencing an AI-powered recommendation system, leading to a lack of trust in the system’s outputs.
TensorFlow Differential Module
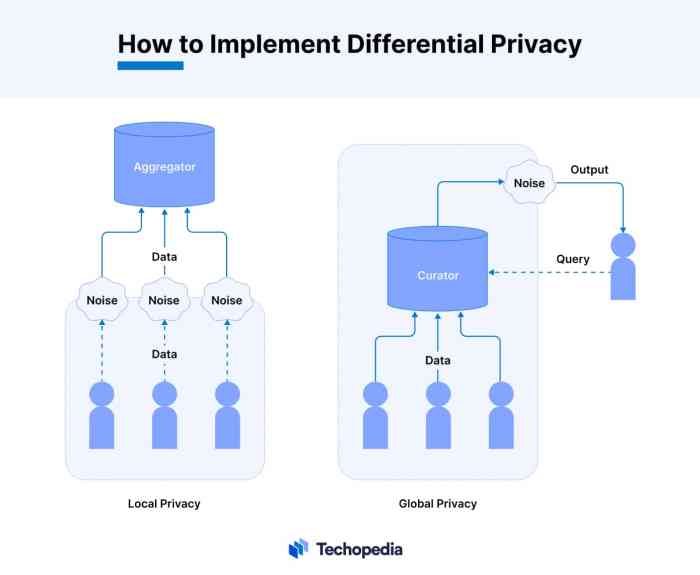
The TensorFlow Differential Module (TFDM) is a powerful component within the TensorFlow ecosystem, designed to streamline and optimize the training process of machine learning models. It provides a framework for efficiently calculating gradients and performing automatic differentiation, crucial steps in algorithms like stochastic gradient descent (SGD). This module’s effectiveness stems from its ability to handle complex models and computations with remarkable speed and accuracy.
Functionality and Purpose
The TensorFlow Differential Module facilitates the automatic computation of derivatives for various mathematical operations. This capability is fundamental to many machine learning algorithms, particularly those relying on gradient descent for optimization. By automating the differentiation process, TFDM frees developers from manually implementing complex calculus operations, allowing them to focus on the higher-level design and logic of their models.
Contribution to AI Model Training and Optimization
TFDM significantly accelerates AI model training by automating the calculation of gradients. Gradient information is essential for adjusting model parameters during training to minimize error. By automatically computing gradients, TFDM allows for faster convergence and more efficient learning, reducing the time and computational resources needed for training. This automated process is especially beneficial for complex models with numerous parameters.
It facilitates the optimization of intricate neural networks, enabling the training of sophisticated models that can address complex tasks.
Mathematical Principles
The core of TFDM lies in automatic differentiation, which leverages the chain rule of calculus to efficiently compute gradients. It utilizes a technique called “computational graph,” where operations are represented as nodes connected by edges. The graph structure enables the efficient propagation of gradients through the model. This allows for the calculation of the gradient of the loss function with respect to each model parameter, providing the direction for adjustments during optimization.
The mathematical principles underpinning TFDM ensure the accuracy and reliability of gradient calculations. The process of calculating gradients involves representing the model’s operations as a graph of interconnected nodes. Each node represents a specific mathematical operation, and the edges represent the flow of data between them. The chain rule is applied recursively to calculate the gradients, flowing backward through the graph.
Practical Applications
TFDM finds widespread application in various AI tasks. For instance, in image recognition, it enables the training of deep convolutional neural networks. By automatically calculating gradients, it accelerates the learning process and allows for the development of models capable of accurately identifying objects and patterns in images. Similarly, in natural language processing, TFDM is crucial for training recurrent neural networks (RNNs) and transformers.
These models are essential for tasks like language translation and text generation. Another example includes its use in financial modeling, where TFDM is leveraged to optimize algorithms for risk assessment and prediction. In all these applications, the efficiency and accuracy of TFDM are critical to achieving optimal model performance.
Data Privacy and AI Model Training
AI models, particularly those trained on large datasets, often incorporate sensitive personal information. Protecting this data during the model training process is paramount. Data privacy considerations are not merely an afterthought but an integral part of the model development lifecycle. This involves careful selection, transformation, and management of the data to ensure compliance with regulations and ethical standards.AI model training heavily relies on the quality and integrity of the data used.
Compromising data privacy can lead to significant legal and reputational risks for organizations. Furthermore, violating privacy regulations can result in substantial financial penalties. Therefore, robust data privacy measures are crucial for ethical and responsible AI development.
Data Privacy Considerations in AI Model Training
Protecting individual privacy during AI model training requires a multifaceted approach. This involves a careful assessment of the data used, the potential risks associated with its use, and the implementation of appropriate privacy-preserving techniques. Organizations must adhere to stringent guidelines and regulations regarding data handling, ensuring transparency and accountability throughout the entire process. Failure to address these concerns can have severe consequences for both individuals and organizations.
Anonymization and Pseudonymization Techniques
Data anonymization and pseudonymization are common techniques for protecting sensitive information during AI model training. Anonymization removes identifying information from the dataset, rendering it impossible to link individual data points to specific individuals. This approach, however, can lead to a loss of potentially valuable information if the removed attributes are essential for the model’s predictive capabilities.Pseudonymization, on the other hand, replaces identifying information with unique identifiers.
This method preserves the data’s utility while safeguarding individual privacy. However, careful management of these identifiers is essential to prevent re-identification and maintain the privacy of individuals. For instance, a healthcare dataset might use pseudonyms for patient names while retaining vital medical information for training a disease prediction model.
Google’s AI data privacy, especially in TensorFlow’s differential module code, is a crucial area of study. It’s fascinating how this connects to business strategies like Elon Musk’s approach with the Tesla Model Y, focusing on 3-word-of-mouth marketing strategies, as seen in this insightful article. Ultimately, the core principles of data privacy and AI development need careful consideration in any business model, and that includes Google’s AI products.
Differential Privacy for Preserving Privacy
Differential privacy introduces controlled noise into the data, making it more difficult to infer individual data points. This technique adds carefully calculated noise to the model’s input data, ensuring that the model’s predictions remain relatively consistent even if a single data point is removed or modified. This approach effectively protects individual privacy without significantly impacting the model’s performance. For example, in a model predicting customer churn, adding differential privacy noise to the customer data ensures that the model’s predictions remain accurate while protecting individual customer data.
Comparison of Data Privacy Techniques
| Technique | Description | Advantages | Disadvantages |
|---|---|---|---|
| Anonymization | Removing identifying information | Simple, cost-effective | Loss of potentially useful information |
| Pseudonymization | Replacing identifying information with unique identifiers | Preserves data utility | Requires careful management of identifiers |
| Differential Privacy | Adding noise to data | Protects individual privacy | Can reduce model accuracy |
Privacy-Preserving AI Techniques
Protecting sensitive data while leveraging the power of AI is crucial for responsible development and deployment. Privacy-preserving AI techniques offer a pathway to achieve this balance, enabling the training of accurate models without compromising the confidentiality of the underlying data. These methods are becoming increasingly important as the use of AI expands across various sectors, from healthcare to finance.Privacy-preserving AI techniques are vital in mitigating risks associated with data breaches and maintaining user trust.
These methods are not just theoretical; they are practical solutions being implemented in real-world applications, ensuring responsible data handling in the age of AI.
Federated Learning
Federated learning allows multiple parties to collaboratively train a shared model without exchanging their raw data. Each party trains a local model on their private data and shares only model updates, such as weights and biases, with a central server. This method significantly enhances data privacy, as the raw data never leaves the control of the individual parties.The model’s updates are aggregated to improve the overall model’s accuracy.
Google’s AI data privacy, particularly in TensorFlow’s differential module code, is fascinating. It’s intriguing how this translates to future devices, like the rumored Google Pixel 9 Pro fold google pixel 9 pro fold release date ai. Ultimately, these advancements in AI data handling will shape the future of personal tech, impacting everything from phone design to how we interact with our data.
The implications for the TensorFlow differential module code are significant.
This iterative process is similar to a distributed training approach but emphasizes the crucial element of privacy. This approach is particularly suitable for scenarios involving sensitive data, such as medical records or financial transactions, where centralized storage of data is undesirable or impossible.
Homomorphic Encryption
Homomorphic encryption enables computations to be performed on encrypted data without needing to decrypt it. This technique allows AI models to be trained directly on encrypted data, ensuring that sensitive information remains confidential. The computations performed on the encrypted data yield results that, when decrypted, are equivalent to the computations performed on the original, unencrypted data.This method is powerful, but it comes with computational challenges.
The encryption and decryption processes can be computationally intensive, impacting the efficiency of the AI model training process. However, ongoing research and development are steadily improving the efficiency and applicability of homomorphic encryption in AI. For example, practical applications in secure data analytics are starting to emerge.
Secure Multi-Party Computation, Google ai data privacy tensorflow differential module code
Secure multi-party computation (MPC) allows multiple parties to collaboratively compute a function over their private inputs without revealing those inputs. In AI, this can be used for tasks like training a model on data from different sources without sharing the individual datasets. The result of the computation is known to all parties, but their individual inputs remain confidential.Several cryptographic protocols form the basis of MPC.
These protocols are designed to protect the confidentiality of each party’s input data, enabling computations to be performed securely. The cryptographic techniques underpinning MPC are complex, but their application is significant for ensuring privacy-preserving AI solutions.
Comparison of Privacy-Preserving Techniques
| Technique | Strengths | Weaknesses |
|---|---|---|
| Federated Learning | Preserves data privacy, improves model accuracy (often). Relatively easier to implement in many cases. | Requires significant communication infrastructure, potentially impacting model accuracy depending on the data distribution. |
| Homomorphic Encryption | Enables computations on encrypted data, ensuring data confidentiality. | Complex to implement, can reduce efficiency significantly compared to standard training methods. |
| Secure Multi-Party Computation | Enables secure computation without sharing data, highly versatile. | Computationally intensive, often requiring specialized hardware and software. |
Google AI Data Privacy and TensorFlow
Google’s commitment to data privacy is increasingly crucial in the age of AI. TensorFlow, Google’s open-source machine learning framework, plays a pivotal role in this, offering tools and techniques to ensure responsible and ethical AI development. This exploration dives into the specific data privacy measures within TensorFlow, comparing Google’s practices with competitors, and examining the impact on model development.Google’s approach to AI data privacy is multifaceted, encompassing both the underlying framework and the broader ecosystem.
This section examines how TensorFlow integrates privacy-preserving mechanisms, demonstrating how it empowers developers to build models while respecting user data.
TensorFlow’s Data Privacy Implementations
TensorFlow provides several mechanisms to enhance data privacy during model training. Differential privacy, a technique that adds carefully controlled noise to model outputs, is a key element. This noise obscures individual data points while maintaining the overall statistical patterns of the data. This approach safeguards individual privacy while enabling accurate model training.Another crucial implementation is federated learning.
Instead of collecting data in a central location, federated learning trains models on distributed devices, keeping data local. This approach minimizes the exposure of sensitive data to a central server. This technique is especially useful for privacy-sensitive data, such as medical records or financial transactions.
Comparison with Other Leading Providers
Comparing Google’s data privacy practices with other leading providers reveals a range of approaches. Some competitors prioritize specific aspects of privacy, like anonymization techniques, while others focus on federated learning. Google’s approach stands out with its comprehensive ecosystem of tools and techniques, encompassing differential privacy, federated learning, and end-to-end encryption. These tools, integrated within TensorFlow, offer a robust framework for developers to implement privacy-preserving solutions.
Impact on TensorFlow Model Development
Google’s AI data privacy policies directly influence TensorFlow model development. Developers must now consider privacy implications during every stage of model creation, from data collection and preprocessing to training and deployment. This shift encourages responsible AI development practices, ensuring models are built ethically and transparently. For example, a model trained using differential privacy might yield slightly less accurate results than one trained on non-private data, but this trade-off is often worthwhile for maintaining privacy.
TensorFlow Differential Module and Privacy-Preserving Techniques
The TensorFlow Differential Module is a powerful tool for incorporating privacy-preserving techniques into TensorFlow models. This module allows developers to easily integrate techniques like differential privacy into their model training process. It simplifies the integration of these techniques, allowing researchers and developers to focus on the core machine learning tasks while benefiting from data privacy safeguards. By streamlining the process, the Differential Module makes it easier to create models that respect individual privacy while achieving desired accuracy.
For instance, adding differential privacy noise to the model’s gradients during backpropagation directly impacts the model’s weights, ensuring that individual data points have limited influence on the final model.
Digging into Google AI’s data privacy with TensorFlow’s differential module code is fascinating, but it’s also worth considering broader societal impacts. A recent win for young plaintiffs in a landmark climate lawsuit, like another win for young plaintiffs in a landmark climate lawsuit , highlights the urgent need for responsible development and deployment of powerful technologies like Google’s AI.
Ultimately, the ethical implications of Google AI data privacy and TensorFlow differential module code are intertwined with the broader future of our planet and society.
Code Examples for Privacy-Preserving AI: Google Ai Data Privacy Tensorflow Differential Module Code
Exploring the practical applications of privacy-preserving techniques in AI models is crucial for building trust and responsible AI systems. This section delves into practical code examples demonstrating data anonymization, federated learning, and differential privacy applied to a specific AI model. These examples showcase the implementation of these techniques within the TensorFlow framework, providing tangible insights into their practical application.
Data Anonymization in TensorFlow
Data anonymization is a fundamental privacy-preserving technique that transforms identifiable data into an anonymized form. This involves replacing sensitive information with pseudonyms or generalizing attributes. TensorFlow provides no specific anonymization functions, but the necessary steps can be easily incorporated using Python libraries.
- To anonymize a dataset, replace sensitive attributes like names, addresses, or social security numbers with unique identifiers or generalized values. For instance, replace specific ages with age ranges (e.g., 20-29, 30-39). Libraries like Pandas and Scikit-learn can facilitate this process.
- Ensure the anonymized data preserves the statistical properties of the original data as much as possible to maintain the validity of downstream AI models. Techniques like k-anonymity or differential privacy can be considered to achieve this balance between privacy and data utility. The choice of method depends on the specific data characteristics and the privacy requirements.
TensorFlow Differential Module in a Privacy-Preserving Context
The TensorFlow Differential Privacy module allows for the incorporation of differential privacy into AI models. This approach introduces carefully calibrated noise into the model’s calculations to ensure that individual data points do not significantly influence the model’s output.
- To use the TensorFlow Differential Privacy module, import the necessary functions. This module offers tools for adding noise to model calculations, enabling privacy-preserving training. The choice of noise level is critical, balancing privacy protection with model accuracy. Excessive noise can diminish model performance.
- Define the model and specify the privacy parameters (noise level, sensitivity). These parameters control the level of privacy protection provided. A higher noise level provides stronger privacy guarantees but may result in a less accurate model. Consider the trade-off between privacy and accuracy in the context of the specific task.
- Train the model using the Differential Privacy module. This involves incorporating the added noise into the model’s training process. The training process may be slightly slower than standard training due to the noise injection.

Federated Learning in TensorFlow
Federated learning is a distributed machine learning approach where data remains on individual devices (e.g., smartphones, IoT sensors) instead of being centralized. This decentralized approach enhances privacy by avoiding the transfer of sensitive data.
- Employ TensorFlow Federated (TFF) to implement federated learning. TFF provides tools for data aggregation and model updates without revealing individual data points. The TFF framework facilitates this process by allowing for the secure communication of model updates among devices.
- Design the training process to allow each device to train a local model on its data. These locally trained models are then aggregated and used to update a global model. The process preserves the privacy of individual data by keeping it localized. The key is in the secure aggregation of local model updates without compromising the integrity of the overall learning process.
Privacy-Preserving Image Recognition
Consider a scenario where an AI model is trained to identify objects in images. The application of privacy-preserving techniques can ensure the protection of user data even if the training data comes from images collected by cameras.
- Employ techniques like differential privacy to train an image recognition model. The model is trained with noise added to the training data to protect the privacy of the individual images. The noise level should be carefully adjusted to ensure a good balance between privacy and model accuracy.
- Use federated learning to train the image recognition model on distributed datasets. This decentralized approach allows each device (e.g., a camera) to train a local model on its image data, preventing the centralized collection of all image data. The aggregation of local model updates occurs in a privacy-preserving manner.
Security Considerations in AI
AI models, particularly those trained on sensitive data, pose unique security risks. Protecting the integrity and confidentiality of this data is paramount. Vulnerabilities in AI systems can lead to breaches of privacy, financial losses, and reputational damage. Robust security measures are essential to mitigate these risks.
Security Risks Associated with AI Models
AI models trained on sensitive data are vulnerable to various attacks. Compromised models can leak private information, leading to identity theft or financial fraud. Malicious actors might manipulate the model’s output to achieve their objectives. For example, an AI model trained on medical data could be exploited to predict patient health outcomes inaccurately, leading to misdiagnosis or inappropriate treatment.
Secure Storage and Transmission of Data
Ensuring secure storage and transmission of data is crucial for safeguarding sensitive information. Data should be encrypted both in transit and at rest. Access controls should be implemented to limit access to authorized personnel. Secure communication channels should be used for data transfer. Data should be stored in a physically secure environment.
Regular security audits and penetration testing can help identify and address potential vulnerabilities.
Mitigating Security Vulnerabilities in AI Systems
Implementing robust security measures is vital to mitigate vulnerabilities in AI systems. These measures should include data encryption, access controls, and secure communication protocols. Regular security audits and penetration testing are critical to identifying potential weaknesses and patching them promptly. AI models should be regularly monitored for suspicious activity and anomalies. Techniques such as differential privacy and federated learning can help protect sensitive data used for training.
Developing AI models with inherent security characteristics is important.
Code Examples Demonstrating Security Measures
Implementing security measures in a privacy-preserving AI system involves careful consideration of data handling and model design. A secure system must prioritize encryption, access control, and secure communication protocols. This is exemplified in the following pseudocode:“`# Encryption of data at restimport cryptography# … (Implementation of encryption algorithm)# Access control mechanismdef authorize_access(user_id, data_type): if user_id in authorized_users and data_type in authorized_access: return True else: return False# Secure communication protocolimport ssl# …
(Implementation of secure communication protocol using SSL)# Example of differential privacyimport tensorflow_privacy# … (Implementation of differential privacy using TensorFlow Privacy library)“`The above code snippets illustrate some fundamental security measures. More sophisticated implementations would include more advanced encryption techniques, multi-factor authentication, and intrusion detection systems.
Closing Summary
In conclusion, the intersection of Google AI data privacy and the TensorFlow Differential Module presents a compelling solution for building trustworthy AI systems. By employing various privacy-preserving techniques, like federated learning and homomorphic encryption, we can ensure that sensitive data remains protected while allowing AI models to learn and improve. The code examples and practical applications showcased throughout this exploration highlight the potential of these techniques for a more responsible and secure future of AI.