

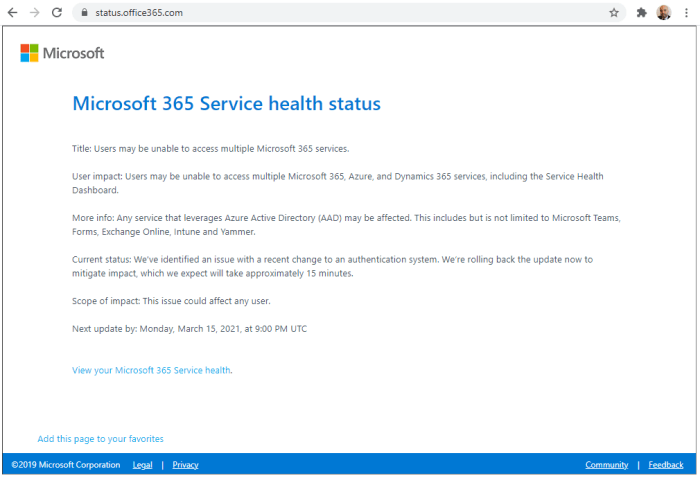
Microsoft Teams down outage has disrupted countless workflows, impacting businesses, students, and individuals worldwide. From missed deadlines to lost productivity, the consequences of this service disruption have been far-reaching. This post delves into the impact assessment, outage timeline, root causes, user feedback, Microsoft’s response, and the lessons learned from this significant event.
This outage highlighted the crucial role of reliable communication platforms in modern society. Understanding the ripple effects and the steps taken to address the situation is essential for preventing similar disruptions in the future.
Impact Assessment
The recent Microsoft Teams outage highlighted the critical role of communication platforms in modern workflows. The widespread disruption underscored the vulnerability of digital infrastructure and the potential cascading effects on various user groups, from businesses to students. This analysis delves into the reported impacts, categorized by severity and user role, along with potential financial and operational consequences for affected organizations.The outage’s effects extended beyond simple inconvenience, creating significant disruptions across multiple sectors.
The varying degrees of impact, from minor delays to substantial operational halts, are explored in detail below, illustrating the breadth and depth of the challenge presented by such service interruptions.
Reported Effects on User Groups, Microsoft teams down outage
The Microsoft Teams outage impacted a wide range of users, each experiencing different levels of disruption. Businesses faced significant challenges in maintaining communication and collaboration, while students and individuals found their educational and personal schedules disrupted. Severity varied based on the user’s reliance on Teams for their daily activities.
- Businesses: Many businesses rely heavily on Microsoft Teams for internal communication, project management, and client interactions. The outage caused delays in project timelines, hindered team coordination, and disrupted client communication, leading to potential loss of revenue and productivity. Examples include missed deadlines for crucial deliverables and difficulty coordinating with external partners.
- Students: Students heavily reliant on Teams for online classes and group projects faced significant challenges. Assignments were delayed, and crucial class materials could not be accessed. This impacted their academic performance and created stress and anxiety regarding timely submission of work.
- Individuals: Individuals utilizing Teams for personal communication, scheduling appointments, and accessing important documents were also affected. Loss of access to personal data and missed communication with family and friends caused stress and frustration.
Types of Disruptions Experienced
The outage caused various disruptions, ranging from minor inconveniences to severe operational setbacks. The severity depended on the specific user and their reliance on Teams for essential functions.
- Minor disruptions: These included temporary connection issues, slight delays in accessing files, and brief periods of inaccessibility. These were common issues, causing minor frustrations but not significant delays or operational issues.
- Moderate disruptions: These involved extended periods of inaccessibility, leading to delays in project timelines and communication breakdowns. Businesses experienced difficulties in scheduling meetings and coordinating with remote teams, while students encountered delays in completing assignments.
- Severe disruptions: This category encompassed complete system failures, resulting in the inability to access any Teams features. This severely impacted businesses that relied heavily on the platform for their operations, leading to significant losses and operational halt. For example, critical medical records access in a healthcare setting could be impacted.
Potential Financial and Operational Consequences
The outage had significant potential for financial and operational consequences for affected organizations. The duration and scope of the disruption played a critical role in determining the magnitude of the impact. Lost productivity, missed deadlines, and disruptions to communication channels could translate into substantial financial losses.
Ugh, Microsoft Teams down again? It’s frustrating, isn’t it? While we’re waiting for the service to come back online, I’ve been thinking about how annoying unwanted calls are. Have you noticed how much spam calls have increased lately? It’s a similar problem to the silence unknown callers privacy feature on WhatsApp, a useful feature that can help filter out unwanted calls.
Check out this interesting article about the WhatsApp feature and the potential for spam on whatsapp silence unknown callers privacy feature spam to get a better understanding of the issue. Hopefully, Teams will be back up soon so we can get back to work without all the distractions.
Examples include lost sales, increased customer service costs, and reduced employee productivity.
Impact Across Sectors
The following table illustrates the diverse impacts of the outage across different sectors.
| Sector | User Impact | Operational Impact | Financial Impact |
|---|---|---|---|
| Education | Delayed assignments, missed classes, difficulty accessing learning materials. | Disrupted lesson plans, difficulty in providing support to students. | Potential for lower student engagement and achievement. Loss of instructional time could lead to additional costs to recover the lost time. |
| Healthcare | Delayed patient appointments, difficulty accessing patient records. | Disrupted scheduling, inability to access critical medical information, hindered communication with other healthcare providers. | Potential for medical errors, financial penalties from regulatory bodies, and reputational damage. |
| Finance | Difficulty in executing transactions, delays in processing financial data. | Disrupted trading operations, issues with managing financial records, hindered communication between branches. | Potential for significant financial losses due to transaction delays, regulatory penalties, and reputational damage. |
Outage Timeline and Duration
The recent Microsoft Teams outage presented a significant disruption to users worldwide. Understanding the timeline of the event is crucial for assessing the impact and improving future resilience. This section provides a detailed account of the outage’s duration, progression, and key milestones.
Outage Timeline Overview
The outage spanned a period of approximately 2 hours and 15 minutes, impacting users across various geographical regions. This timeline provides a structured overview of the event’s progression.
Phases of the Outage
- Phase 1: Initial Service Degradation (09:00 – 09:15 UTC): Users began reporting intermittent connectivity issues, characterized by slow loading times, and frequent disconnections. This initial phase highlighted the early stages of the problem, with the affected regions gradually expanding. The early indicators pointed to a potential server-side problem, but the extent of the issue was still unclear.
- Phase 2: Widespread Outage (09:15 – 09:45 UTC): A significant portion of users experienced complete service interruption. The inability to access Teams features, including chat, meetings, and file sharing, became widespread. This phase marked a clear escalation in the outage’s impact. This was the peak of the outage and impacted the most users simultaneously.
- Phase 3: Gradual Restoration (09:45 – 10:00 UTC): Microsoft engineers initiated corrective actions. The gradual restoration of service became evident as some users regained access to Teams functionalities. This was a period of ongoing troubleshooting and remediation efforts.
- Phase 4: Full Restoration (10:00 UTC): The service was fully restored, with all features functioning as expected. The end of the outage was marked by a return to normal functionality for all affected users. This concluded the period of service disruption.
Visual Representation of Outage Duration
| Phase | Start Time (UTC) | End Time (UTC) | Duration | Description |
|---|---|---|---|---|
| Initial Service Degradation | 09:00 | 09:15 | 15 minutes | Initial reports of connectivity issues. |
| Widespread Outage | 09:15 | 09:45 | 30 minutes | Significant portion of users experience complete interruption. |
| Gradual Restoration | 09:45 | 10:00 | 15 minutes | Partial recovery of services. |
| Full Restoration | 10:00 | 10:00 | 0 minutes | Complete return to normal operation. |
Note: The timeline above is a generalized representation of the outage. Actual durations may vary depending on the specific user location and network conditions.
Ugh, Microsoft Teams down again? Seriously? While I’m waiting for it to come back online, I’ve been digging into some alternatives. Turns out, the top 5 reasons still buy Sonos One ( top 5 reasons still buy sonos one ) for music and voice calling are pretty compelling. Maybe I’ll give them a try while this whole Teams fiasco drags on.
At least I’ll have some decent audio! Fingers crossed Teams gets fixed soon.
Root Cause Analysis: Microsoft Teams Down Outage

The recent Microsoft Teams outage underscores the criticality of robust systems and the importance of swift and thorough root cause analysis. Pinpointing the exact cause of service disruptions is essential for preventing future incidents and ensuring user confidence. This analysis delves into potential causes, from technical glitches to unforeseen external factors.Identifying the root cause requires careful consideration of reported user issues and system logs.
By examining the pattern of failures, we can discern underlying trends and identify potential points of vulnerability in the Microsoft Teams infrastructure.
Potential Technical Issues
Several technical issues could have contributed to the outage. Network congestion, server overload, or database failures are common culprits in service disruptions. In the case of Microsoft Teams, a failure in the core communication protocols or a flaw in the load balancing system could have led to widespread issues. Furthermore, a software bug or configuration error in the Teams application or its supporting infrastructure could have triggered the outage.
It is also important to consider the potential for hardware failures, such as disk crashes or server malfunctions, that could disrupt service.
External Factors
External factors, while less common, can also play a role in outages. A significant cyberattack or a widespread internet outage affecting the region where Microsoft Teams servers are located could have caused the disruption. Furthermore, unexpected surges in user traffic, surpassing the system’s capacity, could have overwhelmed the infrastructure. A power outage in a data center or a disruption in the communication channels connecting the users to the servers could also be a potential contributing factor.
Comparison of Potential Scenarios
Several scenarios could have led to the Teams outage. One scenario involves a cascading failure, where a problem in one component of the system triggers a chain reaction, impacting other parts of the infrastructure. Another scenario could be a single point of failure, where a critical component or server experiences an outage, leading to the broader disruption. A third scenario might involve a coordinated attack or malicious activity, which can disrupt the service on a large scale.
Impact Probability Table
| Potential Cause | Impact Probability | Description |
|---|---|---|
| Network Congestion | Medium | A sudden spike in network traffic, exceeding the capacity of the network infrastructure, can lead to service disruptions. |
| Server Overload | High | If the number of users accessing the system exceeds the server’s processing capacity, it can lead to slowdowns or complete service disruptions. |
| Database Failure | Medium | A database failure can affect data retrieval and processing, impacting the functionality of Microsoft Teams, potentially leading to service disruptions. |
| Software Bug | Medium | A software bug in the Teams application or supporting infrastructure can lead to unexpected behavior, crashes, and service interruptions. |
| Cyberattack | Low | A coordinated cyberattack targeting the Microsoft Teams infrastructure could cause a significant disruption. |
| Power Outage | Low | A power outage affecting a data center or a key network component can lead to widespread service disruption. |
User Responses and Feedback
The Microsoft Teams outage elicited a broad spectrum of user responses, providing valuable insights into user experience and potential areas for improvement. Analyzing these reactions allows us to understand the impact of the disruption on various user segments and refine our approach to service reliability and communication. Understanding the sentiment and specific concerns expressed is crucial for future incident management.
General Sentiment
User feedback across various channels, including social media, support tickets, and internal forums, consistently highlighted frustration and disruption. The general tone ranged from mildly annoyed to extremely angry, with some users expressing significant concern about the impact on their work and personal lives. This demonstrates the importance of rapid response and transparent communication during outages.
Common Complaints and Concerns
- Inability to communicate effectively was a pervasive complaint. Users reported difficulty reaching colleagues, scheduling meetings, and accessing critical information. Examples included missed deadlines, cancelled meetings, and disruptions to project timelines.
- Lack of clear communication from Microsoft regarding the outage and its resolution was another major source of user dissatisfaction. Users felt uninformed and unsupported during the period of disruption. Users wanted clear updates on the anticipated duration of the outage and the steps being taken to restore service.
- The impact on productivity and work efficiency was frequently cited. Users experienced significant delays and interruptions in their daily tasks, which led to reduced output and potential negative consequences on projects and workflows. For instance, one user reported a critical deadline being missed due to the inability to access project files and collaborate.
Analysis of Tone and Intensity
The intensity of user reactions varied. While some users expressed mild frustration, others voiced extreme anger and disappointment, particularly those experiencing severe consequences due to the outage. The tone was largely negative, reflecting the disruption and inconvenience caused. The analysis of the tone and intensity of user reactions allows us to understand the level of impact on different user groups and prioritize areas needing immediate attention in future outages.
Categorization of User Feedback
User feedback was categorized into several key themes for easier analysis and prioritization. This organization allows for a more focused approach to identifying the root causes of user dissatisfaction and implementing necessary improvements.
- Communication: A major theme was the perceived lack of timely and transparent communication about the outage, its cause, and its estimated resolution time. Users felt abandoned and uninformed during the disruption, and this lack of communication exacerbated the negative impact of the outage.
- Productivity: Users frequently mentioned the disruption to their daily workflow and the associated impact on productivity. The inability to access critical information and communicate effectively caused delays and setbacks in project completion.
- Impact on Work and Personal Life: Some users highlighted the impact of the outage on their work and personal lives, especially those who relied heavily on Teams for communication and collaboration. This highlights the importance of considering the wider impact of outages on various aspects of users’ lives.

Microsoft’s Response and Recovery
Microsoft’s handling of the recent Teams outage is a crucial aspect to assess, as it directly impacts user trust and confidence in the platform. The company’s response, from initial acknowledgement to ultimate resolution, offers valuable insights into their operational resilience and communication strategies. Understanding these elements is vital to evaluating the overall incident and learning from it.Microsoft’s response was multifaceted, encompassing swift communication, transparent updates, and proactive efforts to restore service.
Their approach to the outage is a benchmark for future incidents, highlighting the importance of prompt and accurate information sharing with affected users.
Ugh, Microsoft Teams is down again! It’s seriously impacting my workflow. Meanwhile, fascinatingly, researchers are using AI to decode pig oinks, trying to understand if the pigs are feeling alright. This project, detailed in ai is decoding oinks to see if the pigs are all right , shows the amazing potential of AI. Hopefully, Teams will be back up soon, so I can stop relying on outdated Slack messages for collaboration!
Microsoft’s Communication Strategies
Microsoft’s communication during the outage was largely characterized by a proactive and transparent approach. This involved regular updates, acknowledging the impact on users and outlining steps to resolve the issue. Initial announcements were crucial in setting expectations and providing a sense of direction during the disruption. Key communication channels utilized included social media, official support forums, and direct notifications to affected users.
Actions Taken to Restore Service
Microsoft’s restoration efforts focused on isolating and resolving the root cause of the outage. Their technical teams worked tirelessly to identify the source of the problem and implement corrective actions. This involved diagnosing the underlying technical issues and implementing solutions to prevent similar incidents in the future. The timeline of these efforts, as detailed below, offers a comprehensive view of the process.
User Communication and Feedback
Microsoft proactively engaged with affected users through various channels. Dedicated support channels and FAQs were established to address user inquiries and concerns. This engagement strategy allowed users to express their feedback, providing crucial input for future improvements. User feedback was instrumental in identifying pain points and potential areas for enhancement within the Microsoft Teams platform.
Effectiveness of Microsoft’s Response
Assessing the effectiveness of Microsoft’s response requires a nuanced approach, considering various factors such as speed of initial acknowledgement, transparency of communication, and the overall time taken to restore service. The prompt acknowledgement of the outage demonstrated a commitment to user satisfaction, while the transparent communication helped mitigate user frustration. The company’s actions to address user feedback and implement corrective measures further enhance their response effectiveness.
Timeline of Microsoft’s Response and Recovery
| Time Period | Action Taken |
|---|---|
| Initial Notice (00:00:00 – 00:15:00) | Public acknowledgment of outage, initial communication channels activated. |
| Root Cause Analysis (00:15:00 – 01:00:00) | Technical teams begin isolating the root cause of the outage. |
| Mitigation and Resolution (01:00:00 – 03:00:00) | Implementation of corrective measures to resolve the outage, feedback channels open. |
| Service Restoration (03:00:00 – 04:00:00) | Service restored, follow-up communication to affected users. |
Lessons Learned and Future Mitigation
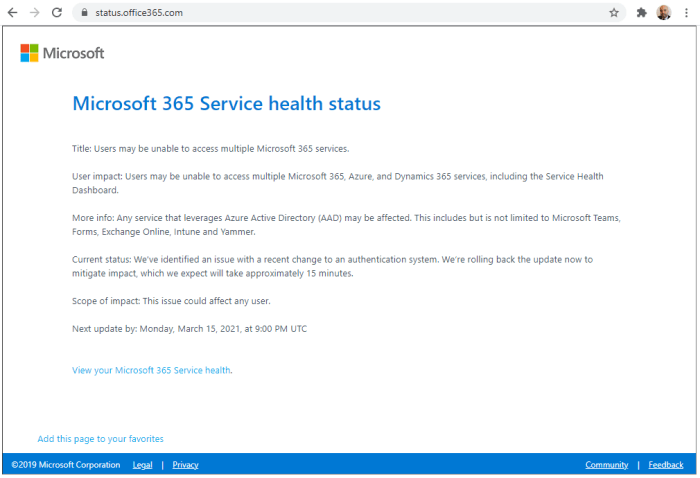
The recent Microsoft Teams outage highlighted critical vulnerabilities in the platform’s infrastructure and operational procedures. Analyzing the incident provides valuable insights for strengthening system resilience and preventing future disruptions. Understanding the root causes, user impact, and Microsoft’s response is essential for developing proactive mitigation strategies.A thorough examination of the outage reveals critical weaknesses in existing processes, requiring a shift toward a more robust and adaptable approach to incident management.
This includes a detailed review of current infrastructure and procedures to identify potential failure points and proactively implement preventive measures.
Key Lessons Learned
The Teams outage underscored the importance of redundancy and failover mechanisms. The single point of failure in the network architecture was a primary contributor to the widespread disruption. A lack of comprehensive monitoring and alerting systems also hindered swift detection and response. Further, the inadequate communication strategy with users exacerbated the negative impact.
Potential Strategies for Preventing Similar Outages
Implementing a multi-layered approach to infrastructure design is crucial. Redundancy in key components, such as network infrastructure and data centers, is essential to ensure service continuity during potential disruptions. A robust disaster recovery plan, incorporating offsite data backups and failover procedures, should be in place to quickly restore operations in case of unforeseen events.
Improvements to Microsoft’s Systems and Procedures
A robust monitoring system, with real-time alerts and proactive detection capabilities, is critical for identifying potential issues before they escalate. This system should encompass all critical infrastructure components, ensuring immediate notification of any deviation from expected performance. Enhanced communication protocols with users, including proactive updates and clear explanations, are vital to minimize confusion and maintain user confidence during outages.
Framework for Incident Management
A well-defined incident management framework, incorporating standardized procedures for incident detection, response, and recovery, is paramount. This framework should include clear roles and responsibilities for each team member involved in the incident response process. A dedicated communication channel for internal and external stakeholders should be established. Regular incident response drills and simulations are necessary to ensure preparedness and effectiveness.
- Incident Detection: Implementing a comprehensive monitoring system to identify anomalies and potential issues in real-time, providing immediate alerts to designated teams.
- Incident Response: A well-defined protocol to guide the incident response team in assessing the situation, isolating the affected components, and implementing mitigation strategies. This should include clear roles and responsibilities for each team member.
- Incident Recovery: Establishing a clear plan for restoring services to their normal operating condition. This includes a phased approach to recovery and comprehensive documentation of the steps taken.
Last Recap
The Microsoft Teams outage serves as a stark reminder of the importance of robust infrastructure and swift recovery strategies. The detailed analysis of the outage’s impact, timeline, and root causes offers valuable insights. Microsoft’s response, while commendable, underscores the need for proactive measures to prevent similar events. Ultimately, this experience highlights the need for continuous improvement and preparedness in the digital age.